

NVIDIA's marketing line is "one B200 replaces three H100s." Per MLPerf v4.1 training data, the real ratio is 2.2x per server for training. Per Spheron's MLPerf v5.1 inference data, it's 2.9x for FP8 Llama 2 70B and up to 4-7x for FP4-friendly workloads. The right sizing answer depends on what you're doing (training, inference, or fine-tuning) and which bottleneck dominates your specific workload. This guide walks through the per-GPU ratios, the memory-bound vs compute-bound framing that decides them, and a sizing worksheet for B200 vs H100 cluster decisions in 2026.
- Real measured B200-to-H100 ratios: 2.2x per server for training (NVIDIA MLPerf v4.1), 2.9x for FP8 Llama 2 70B inference (Spheron MLPerf v5.1), and 4-7x for FP4-friendly inference (varies by model and framework). The marketing "3x training, 15x inference" headline applies to specific best-case configurations
- Training is compute-bound. Inference at typical batch sizes is memory-bandwidth-bound. That changes the sizing answer: fewer B200s often beat more H100s for inference even when raw compute looks even, because B200's 8 TB/s HBM3e bandwidth is 2.4x H100's 3.35 TB/s
- Memory capacity sets the floor. A 70B model in FP16 (140 GB) does not fit on a single H100's 80 GB. The minimum is 2 H100s with model parallelism, or 1 H200 (141 GB), or 1 B200 (192 GB). Fitting the model in fewer GPUs reduces interconnect overhead and often wins on TCO even at higher per-GPU cost
- For models above 150B parameters, B200 typically delivers 50% lower total training cost than H100 despite the higher per-GPU rate, per TensorPool's 2025 analysis. For models under 30B parameters, H100 often wins on cost-per-tokens-output
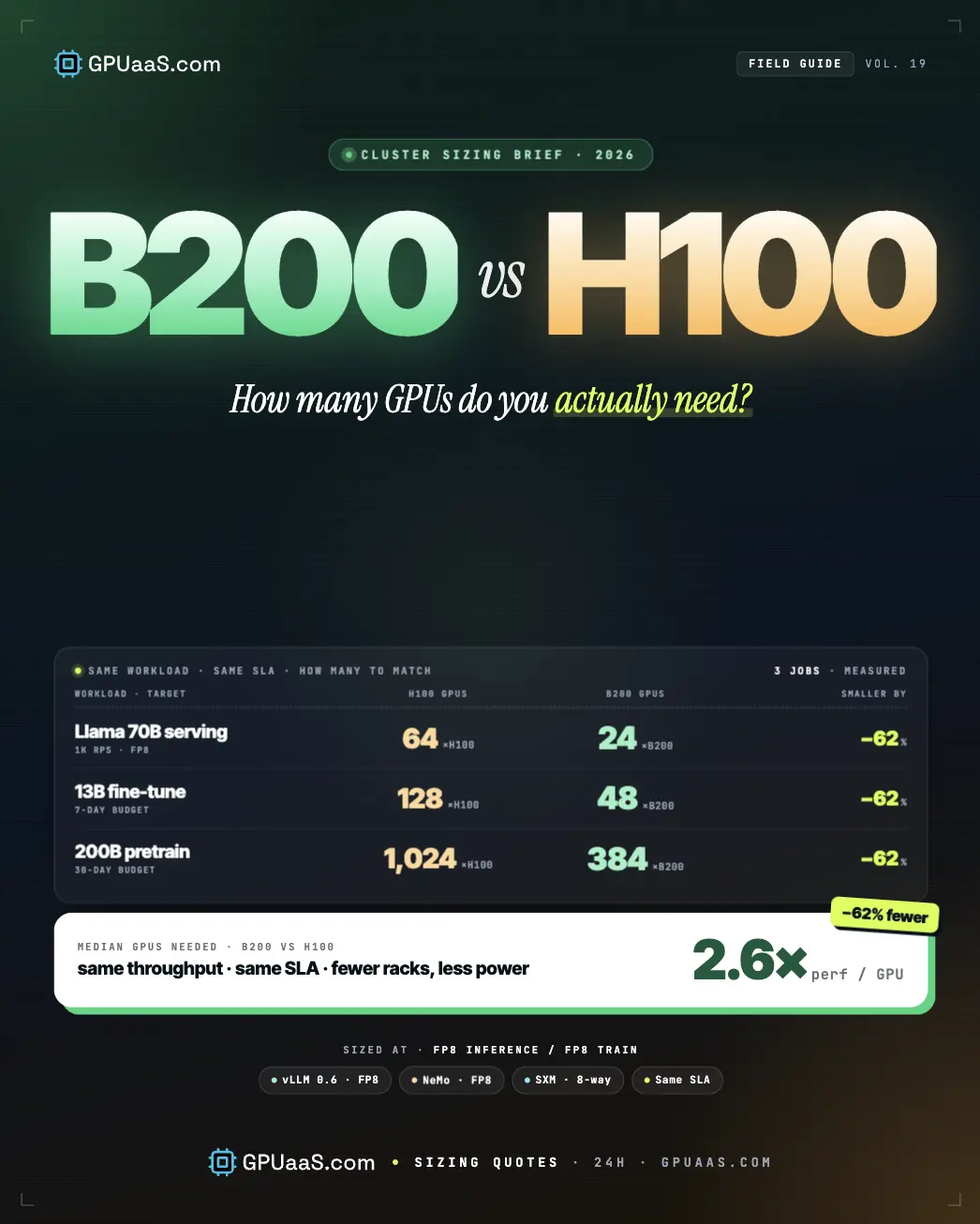
- Real cluster sizing example: NVIDIA's MLPerf v5.0 GPT-3 pretraining used 64 Blackwell GPUs to match performance that required 256 H100s. That is a 4x reduction in cluster size for the same training throughput
- GPUaaS.com offers H100 from ~$2.50/GPU/hr, H200 from ~$3.00/GPU/hr, B200 and B300 from ~$4.50/GPU/hr on flexible contracts with no multi-year lock-in and no egress markup
"How many GPUs do I need?" is the wrong opening question for a cluster sizing decision. The right one is: "How many GPUs of which kind, for which workload, and at what utilisation target?" The answer often surprises buyers in both directions. Sometimes fewer B200s beat more H100s; sometimes more H100s beat fewer B200s. The variables that decide it: model size, precision (FP16 / FP8 / FP4), workload type (training vs inference vs fine-tuning), interactivity target, and contract length. This guide gives you the framework for sizing a B200 vs H100 cluster from your workload, not from a generic "B200 is 3x faster" assumption. For the related cost-per-token math after sizing, see B200 cost per million tokens, measured.
Here are the measured B200-to-H100 per-GPU ratios from 2026 MLPerf data and independent benchmarks, by workload type:
| Workload | B200-to-H100 ratio | Source / conditions |
|---|---|---|
| LLM pretraining (GPT-3 class) | 2x faster per GPU | NVIDIA MLPerf Training v4.1 / v5.0; GPT-3 with HGX B200 |
| LLM fine-tuning (Llama 2 70B) | 2.2x per server | NVIDIA MLPerf Training v4.1; HGX B200 vs HGX H100 server-level |
| Inference, FP8 (Llama 2 70B) | 2.9x per GPU | Spheron MLPerf v5.1 (Sep 2025); 8-GPU B200 vs 8-GPU H200 offline mode |
| Inference, FP4 (GPT-OSS-120B) | ~4-7x per GPU | NVIDIA Developer / Inworld (Apr 2026); ~$0.02/M B200 vs ~$0.14/M H100 |
| Inference, peak headline | up to 15-30x | NVIDIA marketing; specific best-case configurations only |
Sources: NVIDIA MLPerf Training v4.1 and v5.0; Spheron Best GPU for AI Inference 2026 (April 2026); NVIDIA Developer Deep Learning Performance Hub; Inworld B200 GPU guide (April 2026); Clarifai NVIDIA B200 vs H100 comparison.
Three honest things to know about these numbers:
- The "15x to 30x inference" headlines are real but narrow. They apply to FP4 inference on Blackwell-native models where H100 has no FP4 hardware path. For FP8 or FP16 inference where both GPUs have a sensible path, the ratio collapses to 2-4x.
- Training ratios are remarkably consistent at ~2-2.2x. Both NVIDIA's official MLPerf submissions and independent benchmarks converge here. The training compute throughput per GPU is what changed; FP4 doesn't help training because gradients need higher precision.
- The ratios assume both clusters are well-tuned. A B200 cluster running an outdated TensorRT-LLM version can lose to a well-tuned H100 cluster. Software stack maturity matters as much as silicon.
Per CoreWeave's MLPerf v5.0 disclosure: H200 instances reached 33,000 tokens per second on Llama 2 70B inference, a 40% improvement over H100. That intra-Hopper jump (1.4x) gives a sense of how much memory bandwidth alone moves the needle before you cross to Blackwell.
The single most important thing to understand for cluster sizing: training is compute-bound and inference at typical batch sizes is memory-bandwidth-bound. These are different bottlenecks. The hardware spec that helps with one doesn't always help with the other.
Training stresses the streaming multiprocessors. The forward pass computes activations, the backward pass computes gradients, and both spend most of their time doing matrix multiplications. The bottleneck is FLOPS. B200 has roughly 2x H100's FP8 dense throughput (4,500 vs 1,979 TFLOPS), which maps roughly to the 2-2.2x training ratio observed in MLPerf data.
Inference is different. At batch size 1, the GPU loads the entire model weight matrix from VRAM for every generated token. The arithmetic intensity drops to a level where the compute units sit idle most of the time, waiting for data to arrive from memory. Per the March 2025 Mind the Memory Gap analysis on arXiv, even large-batch inference remains memory-bound because DRAM bandwidth saturates as the primary bottleneck. The bottleneck is HBM bandwidth. B200 has roughly 2.4x H100's bandwidth (8 TB/s vs 3.35 TB/s), which maps to the 2.9x inference ratio for FP8 Llama 2 70B observed in MLPerf v5.1.
The arithmetic intensity rule
When arithmetic intensity falls below the ridge point (where compute throughput equals memory bandwidth divided by peak FLOPS), the workload is memory-bandwidth-bound. For LLM decode with typical model sizes and batch sizes, you're well below that ridge point. That is why HBM bandwidth matters more than CUDA core count for inference.
Two practical implications for cluster sizing:
- For training clusters, compute throughput is the right sizing metric. An H100 cluster sized for X tokens/second of training output needs ~2x the GPU count of a B200 cluster sized for the same output (assuming the model fits in memory for both).
- For inference clusters, HBM bandwidth is the right sizing metric. An H100 cluster sized for Y tokens/second of inference output needs ~2.4-3x the GPU count of a B200 cluster sized for the same output at the same precision. At FP4, the ratio widens because H100 doesn't have native FP4 support.
For the inference-specific cost math, see B200 cost per million tokens, measured. For the framework around picking the right benchmark configuration, see how to benchmark your workload before committing to B200.
Throughput ratios assume the model fits on the GPU. When it doesn't, the sizing answer flips. Here's the practical memory map for 2026 workloads:
| Model size + precision | Weights only | Minimum GPU(s) needed |
|---|---|---|
| 8B in FP16 | ~16 GB | Any modern GPU (24GB+) |
| 30B in FP16 | ~60 GB | 1 H100 (80GB) |
| 70B in FP16 | ~140 GB | 2 H100s (model parallel), or 1 H200 (141GB), or 1 B200 (192GB) |
| 70B in FP8 | ~70 GB | 1 H100 (tight, 10GB headroom for KV cache) |
| 150B in FP8 | ~150 GB | 2 H100s, or 2 H200s, or 1 B200 |
| 405B in FP8 | ~405 GB | 8 H100s (multi-node typical), or 4 H200s, or 3 B200s |
| 671B MoE (DeepSeek-V3 class) | ~670 GB FP8 | 8-GPU node minimum; GB200 NVL72 rack for low-latency |
KV cache, activations, optimizer state, and framework overhead add 20-40% on top of model weights in inference; for full fine-tuning, add 6-8x for gradients and Adam optimizer state. Numbers above are weights-only; actual headroom needed is higher.
Per Lyceum Technology's February 2026 fine-tuning hardware guide, a 70B parameter model in full fine-tuning requires approximately 1.12 TB of VRAM before considering activations. That puts a 70B full fine-tune at minimum 6 H100s, 6 H200s, or 4 B200s. Parameter-Efficient Fine-Tuning (LoRA / QLoRA) lowers this dramatically because gradient and optimizer state drops, but the base model still has to load fully.
⚠ Watch out
When the model doesn't fit on a single GPU, model parallelism kicks in. The interconnect becomes the bottleneck. Two H100s with NVLink talking through 600 GB/s GPU-to-GPU bandwidth lose efficiency vs one B200 doing the same work in a single GPU's HBM. A "cheaper" 2-H100 deployment can have 1.5-2x worse effective throughput than 1 B200 for a 70B FP16 model, even before factoring per-GPU rate.
Three concrete sizing decisions, with the math behind each. GPUaaS.com contract rates used: H100 ~$2.50/GPU/hr, H200 ~$3.00/GPU/hr, B200 ~$4.50/GPU/hr.
Example 1: Pretraining a 150B-parameter foundation model over 4 weeks.
- Compute requirement: ~1.5 × 10^24 FLOPs total (Chinchilla-scaled training budget)
- H100 cluster: 256 H100s at ~50% MFU delivers the budget in 28 days. Cost: 256 × $2.50 × 24 × 28 = $430,080
- B200 cluster: 128 B200s at ~50% MFU delivers the same in 28 days (2x per-GPU throughput). Cost: 128 × $4.50 × 24 × 28 = $387,072
- B200 wins on TCO by ~10%, and uses half the GPU count. Per TensorPool's 2025 analysis, this gap widens to ~50% for models above 150B parameters where multi-node scaling overhead bites harder on the H100 cluster.
Example 2: Serving Llama 3.3 70B FP8 inference at 50 TPS/user, 1,000 concurrent users.
- Total output throughput required: 50 × 1,000 = 50,000 tokens/sec
- H100 single-GPU throughput at this interactivity: ~1,200 tok/s/GPU sustained (70B fits in 80GB at FP8 with tight KV cache headroom). Need: 50,000 / 1,200 = ~42 H100s. Cost: 42 × $2.50 × 24 × 30 = $75,600/month
- B200 single-GPU throughput at this interactivity: ~3,500 tok/s/GPU sustained (much larger headroom in 192GB, deeper batching). Need: 50,000 / 3,500 = ~15 B200s. Cost: 15 × $4.50 × 24 × 30 = $48,600/month
- B200 wins on monthly TCO by 36%, and uses 65% fewer GPUs. The 65% smaller cluster also draws less power, needs less rack space, and is easier to operate.
Example 3: LoRA fine-tuning Llama 3.3 8B for a customer support use case, single-node deployment.
- Memory requirement: 8B FP16 weights (~16GB) + LoRA gradients/optimizer (~6GB) + batch activations = ~30GB total. Fits comfortably on a single H100.
- H100 single-GPU job time: 8 hours at typical hyperparameters. Cost: 1 × $2.50 × 8 = $20
- B200 single-GPU job time: ~3.5 hours (2.2x faster per the MLPerf v4.1 ratio). Cost: 1 × $4.50 × 3.5 = $15.75
- B200 wins by ~20% on cost and 56% on wall-clock time. The H100 is fine; the B200 is faster to results, which matters for iteration cycles.
The pattern: for workloads where the model is memory-bound or where B200's FP4 hardware path helps, B200 wins on TCO despite the higher per-GPU rate. For small models that fit comfortably on H100 with mature FP8 tooling, the rate gap closes and H100 often wins on cost-per-job. For the inference economics deep-dive, see B200 cost per million tokens and H100 vs H200 vs B200 decision guide.
The B200 doesn't always win. Here are the scenarios where H100 genuinely beats B200 on TCO, despite being the older GPU:
- Models under 30B parameters at FP8. The model fits comfortably on a single H100, B200's larger memory and bandwidth go unused, and the rate gap (1.8x) is wider than the throughput gap (1.2-1.5x at these sizes). H100 wins on cost-per-job. Per the GMI Cloud February 2026 analysis: an H100 at $2.10/hour generating 800 tokens/s costs $0.00073 per 1K tokens. That's competitive with B200 for this size class.
- Workloads with no FP4 path on the model side. B200's headline advantages depend heavily on FP4 native support. Models that haven't been quantised to FP4 or where quantisation degrades quality (some reasoning models, some vision-language models) see B200's advantage collapse to the bandwidth ratio alone.
- Sustained low-utilisation workloads. If your average GPU utilisation is under 30% (research, experimentation, sporadic batch jobs), the B200's higher hourly rate compounds across idle time. Per Cast AI's 2026 data, average GPU utilisation across measured clusters is 5%. At those utilisation rates, the cheaper per-hour H100 wins.
- Workloads that need broad ecosystem maturity, not bleeding-edge throughput. Per Spheron's April 2026 analysis, NVIDIA's TensorRT-LLM stack is mature on Hopper, and most production inference patterns assume Hopper as the floor. Some niche frameworks, third-party kernels, and academic codebases are still H100-first, with B200 support lagging by 3-6 months in some corners.
- Tight short-term contracts. When you need 2-4 weeks of capacity for a specific project, H100's larger installed base usually means lower spot pricing and faster availability than B200. The hourly rate gap also matters less over short durations.
⚡ The H100 rule
If your model fits comfortably on a single H100 at FP8, and your software stack is mature on Hopper, the H100 is almost always the right choice for the next 12 months. Save the B200 upgrade for the workload where you actually need 192GB and 8 TB/s: typically 70B+ models, long-context inference, or full-FP4 deployments.
Sizing the cluster on paper is half the work. The procurement decisions around it move the answer almost as much:
- Size for sustained workload, not peak. A team that sizes the cluster for 100% utilisation at peak traffic ends up paying for idle GPUs 80% of the time. Better: size for 60-70% of peak with burst capacity on a separate contract for spikes. For seasonality patterns, see reserved vs on-demand GPU contracts.
- Pick contract length to match software optimisation horizon. Per NVIDIA Developer (April 2026), B200 cost-per-million-tokens dropped 5x in two months from TensorRT-LLM updates alone. A 36-month commitment locks the GPU rate, not the throughput. You end up paying today's rates for tomorrow's already-discounted performance. A 12-month contract preserves repricing optionality.
- Plan for 30% headroom. Sizing the cluster to barely meet your throughput target leaves no room for traffic spikes, model upgrades, or framework regressions. 30% headroom on top of your calculated need is the practical minimum for production workloads.
- Don't oversize the interconnect for inference. For inference workloads where the model fits per-GPU, NVLink and InfiniBand bandwidth matter much less than for distributed training. A B200 inference cluster on PCIe or modest NVLink is often as good as one on InfiniBand at half the network cost.
- Match the cluster to the team's stack maturity. If the team is on vLLM with stable Hopper tooling, that's a non-trivial advantage. Switching to Blackwell mid-project for a 20% throughput gain often costs more in engineering time than the savings. Time the upgrade for natural breakpoints (new model launch, framework version bump).
GPUaaS.com offers H100, H200, B200, and B300 clusters on flexible contracts with no multi-year lock-in, no egress markup, and quotes within 24 hours. For the broader procurement framing across all GPU tiers, see the real TCO of a GPU cluster in 2026, H100 vs H200 vs B200 decision guide, and the GB200 NVL72 buyer's guide for rack-scale options.
Your search for enterprise GPU compute ends here.
NVIDIA infrastructure at rates hyperscalers won't offer you. H100, H200, B200, B300 clusters. Short-term and long-term contracts. No egress markup. Quotes within 24 hours.
Get a quote on your clusterLast reviewed: June 12, 2026. B200-to-H100 ratio figures from NVIDIA MLPerf Training v4.1 and v5.0 submissions, Spheron Best GPU for AI Inference 2026 (April 2026), Northflank B100 vs H100 analysis, Clarifai NVIDIA B200 vs H100 comparison (January 2026), GMI Cloud H100 vs H200 vs B200 inference guide, WhiteFiber Choosing GPU Infrastructure for LLM Training. Memory and bandwidth specs from NVIDIA H100 Datasheet (2023), H200 Product Brief (2024), and B200 GTC 2024 disclosures. Memory-bound vs compute-bound framing from Mind the Memory Gap (arXiv 2503.08311), Dynamic Memory Compression (arXiv 2403.09636), and VMware LLM Inference Sizing Guide (June 2026). Fine-tuning memory analysis from Lyceum Technology LLM Fine-Tuning Hardware Guide 2026 (February 2026). TCO economics from TensorPool 2025 analysis via Lyceum Technology. GPUaaS.com rates are indicative, contract-based, and quote-dependent.







