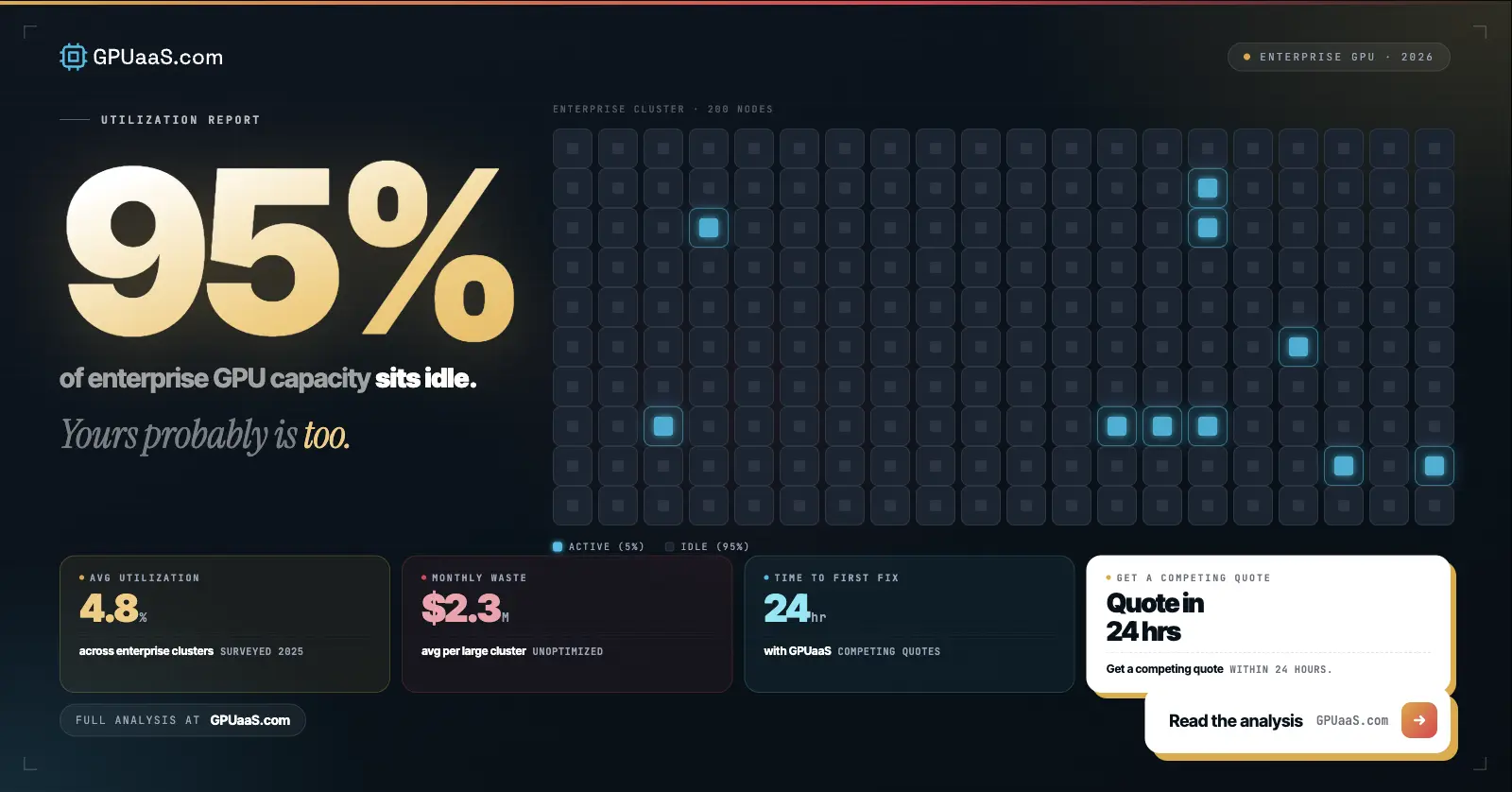
Enterprise GPU buyers are routinely overpaying for compute by ~30%. Add egress, overprovisioning, and lock-in and the real gap is often wider. The silicon is the same. The performance is the same. The only thing different is what sits between the buyer and the GPU. This is a structural breakdown of why wholesale GPU pricing is durably ~30% lower than hyperscale, the exact cost layers driving the gap, and the four-step process to access wholesale rates without a marketplace mark-up.
- Wholesale GPU pricing runs ~30% below hyperscale on-demand for the same silicon, based on published rates as of May 2026 [5]
- AWS H200 on-demand runs ~$10.60/GPU-hr. Wholesale on-demand for the same H200 silicon: $3.79–$4.54/hr — a 57% gap
- For a team at $500K/month on hyperscale GPU, switching to wholesale saves approximately $1.8M/yr on compute — plus up to $600K in egress
- Marketplace and broker intermediaries add 8–15% per transaction; GPUaaS.com removes this layer entirely [1]
- Wholesale quotes arrive in hours, not weeks. No enterprise agreement or quota required
These numbers are not theoretical. They reflect what AI companies, data centres, and enterprise infrastructure teams are signing for right now across the hosted·ai provider network.
In this article
What Hyperscale GPU Pricing Is Actually Buying You Beyond the Silicon
A hyperscaler buys NVIDIA B200, H200, and H100 silicon in volume at acquisition costs far below what any individual buyer could negotiate. By the time that GPU appears as a billable resource on your invoice, it has passed through a long stack of cost layers. None of them are silicon. [1]
The most common enterprise GPU workloads, including model training, fine-tuning, and batch inference, do not need most of those layers. They need the GPU itself, predictable uptime, a sensible SLA, and a path to scale. Paying hyperscale rates means paying for the full stack, in full, whether you consume it or not.
Three Structural Mechanics Driving the Wholesale vs Hyperscale GPU Price Gap
None of these are closing. Each one compounds the others.
Hyperscalers provision in rigid chunks. You rent a node and pay for 100% of it, even when your workload uses 60%. Wholesale providers right-size GPU allocation dynamically. Idle cycles are not billed.
Marketplace and broker intermediaries add 8 to 15% per transaction. GPUaaS.com connects buyers directly to wholesale providers. No intermediary cut, no platform fee.
Wholesale GPU providers do not upsell storage, managed databases, or proprietary ML platforms. Their entire operation is optimised around delivering GPU capacity reliably. That focus produces leaner cost structures and faster provisioning than any general-purpose hyperscaler.
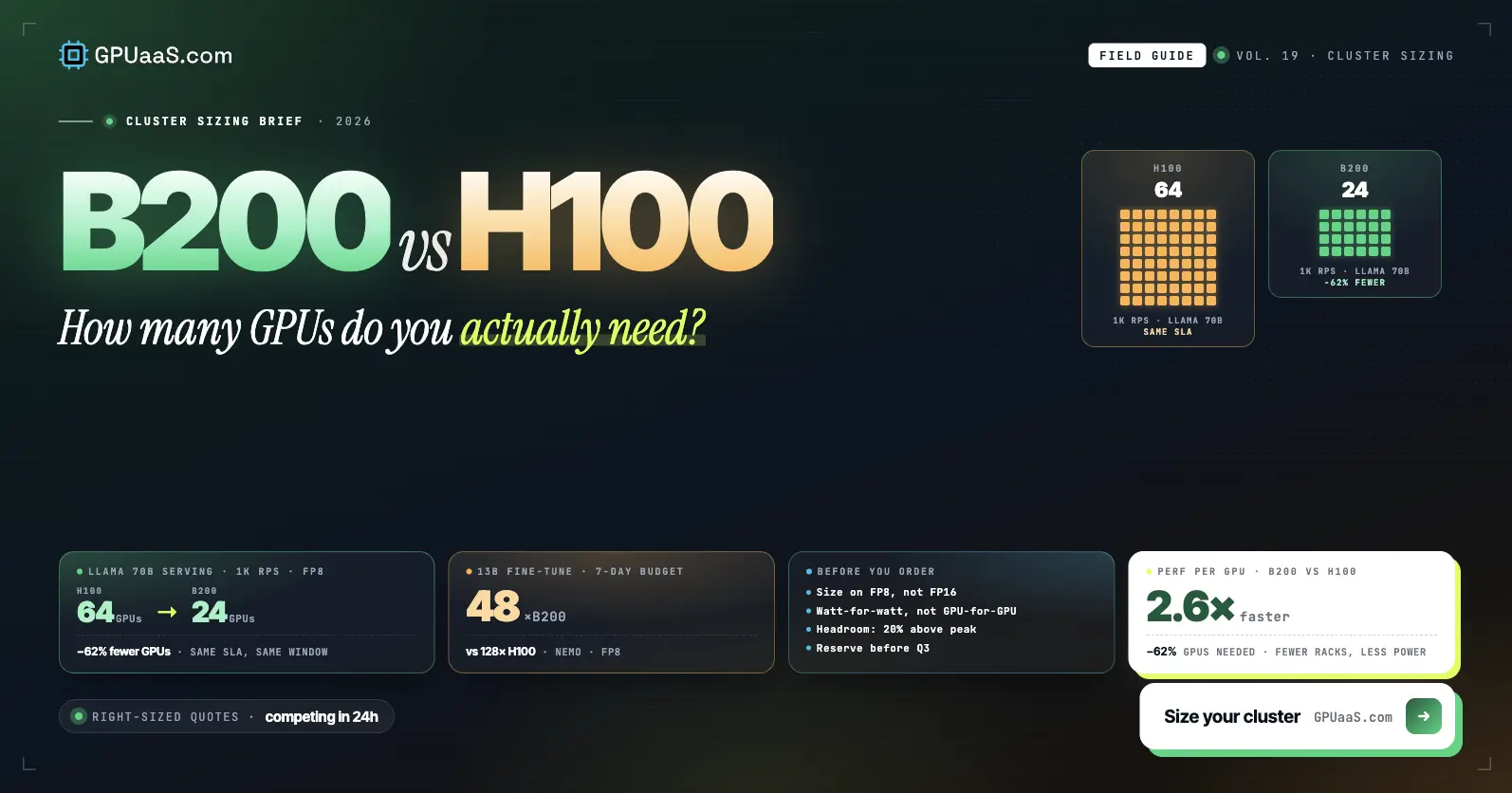
Hyperscale vs Wholesale GPU Pricing Gap by GPU Model: B200, H200, H100
Wholesale GPU access through the GPUaaS.com provider network consistently runs below published hyperscale on-demand rates across all GPU generations.



Savings vs published AWS, GCP, Azure on-demand rates (May 2026). Exact rates vary by configuration, term, and region. Get a quote →
Sources: [5] ThunderCompute, GetDeploying.com, GMI Cloud, Spheron (May 2026). Find the best GPU deal for your workload.
The hidden costs go beyond the headline rate. Training jobs move data: datasets in, checkpoints out, cross-region replication, intermediate state. On hyperscale, every byte that leaves a region is billable. For a serious training pipeline, egress can add 10 to 20% to the effective cost of compute. Factor it in, and the total cost differential frequently exceeds 35%. [4]
Hyperscale GPU commitments often run 1 to 3 years, signed against forecasted demand that is rarely accurate. When workloads change, scale down, or move to a different architecture, the contract does not move with them. Wholesale providers in the hosted·ai network offer flexible 3, 6, and 12-month commitment terms. You commit to what you actually need.
How to Access Wholesale GPU Pricing in Four Steps via GPUaaS.com
GPUaaS.com makes wholesale pricing accessible to any enterprise buyer in four steps. Quotes typically arrive within a few hours at no cost.
Node count, GPU model (B200, H200, H100, A100, RTX Pro 6000), workload type, virtualisation, region, compliance requirements, timeline, and budget range.
GPUaaS.com searches the hosted·ai provider network across N. America, EU, MEA, and APAC, matching requirements against real-time available capacity. Not a price list. Actual capacity, available now.
Quotes come direct from wholesale providers. No markup, no broker layer. GPUaaS.com is a free service from hosted·ai, funded by the provider network. Buyers pay nothing for the match.
Compare quotes on price, term, region, and SLA. Sign directly with the provider. Flexible terms: 3, 6, and 12-month options. No lock-in. No pressure. Provisioning typically completes within days.
Wholesale vs Hyperscale GPU Cost: $500K Monthly Budget Worked Example
Consider an AI infrastructure team running a steady mix of H200 training and B200 inference at $500K per month on hyperscale on-demand rates. The maths is straightforward:
For any team spending mid-six figures or above per month on hyperscale GPU, the annual gap is large enough to fund headcount, additional training runs, or a meaningful margin improvement.
- ✓Running large-scale B200 or H200 training where GPU dominates the cost equation
- ✓Fine-tuning on proprietary data with sovereignty or compliance requirements
- ✓High-throughput steady-state inference where idle GPU billing is the enemy
- ✓Teams with their own MLOps stack not reliant on hyperscaler-proprietary ML services
- ✓Spending $50K/month or more on GPU. The saving compounds quickly at scale
- ○Workload is deeply integrated with proprietary hyperscale ML services and migration cost exceeds GPU savings
- ○GPU usage is genuinely sporadic: very short bursts at irregular intervals
- ○Team has no bandwidth to evaluate and contract with a wholesale provider
As GPU demand grows, hyperscalers are managing enormous infrastructure build programmes alongside investor expectations on margin. The structural incentive to hold pricing at the top of what buyers will pay is growing stronger. Wholesale providers benefit from the same generational GPU improvements through platforms like hosted·ai. Every gain in GPU efficiency on the wholesale side widens the gap. The ~30% premium is not transitional pricing. It is the cost of a different commercial model.
Last reviewed: May 19, 2026. Pricing from [5] ThunderCompute, GetDeploying.com, GMI Cloud, Spheron (May 2026). Capacity data from [6] SemiAnalysis (April 2026). Cost-of-cloud analysis [1] a16z. FinOps data [4] FinOps Foundation. Find wholesale GPU clusters through GPUaaS.com.