The H200 costs 66% less per hour than the B200 at wholesale rates. The B200 completes LLM training jobs roughly 2x faster. Which one saves money depends on what you're running and how long the job takes.
- H200 SXM wholesale on-demand: $3.50–$4.54/hr. B200 SXM: $4.99–$6.19/hr. Hyperscale rates run 2–3x higher for both [1]
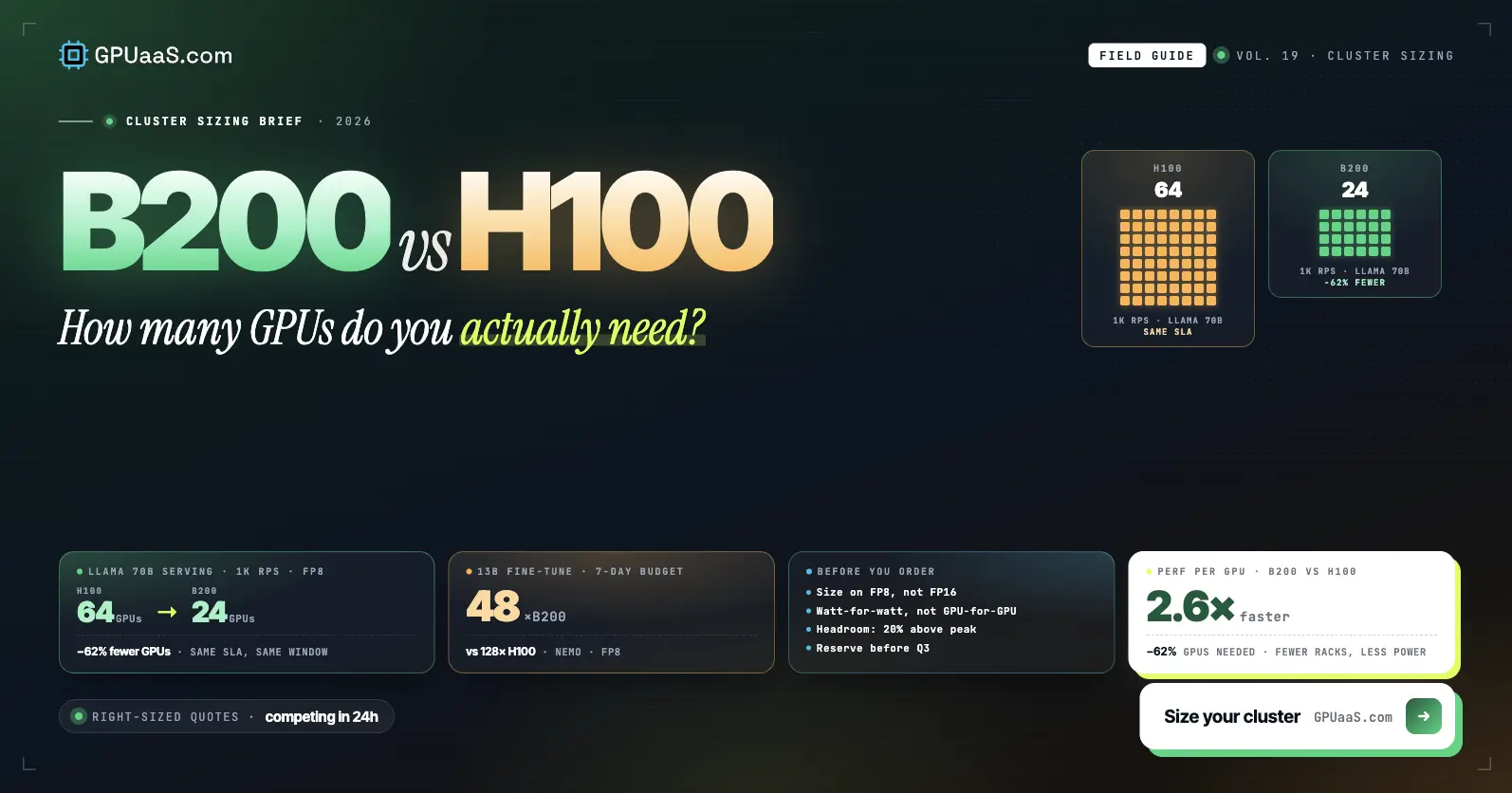
- B200 completes 70B LoRA fine-tuning 2.2x faster than H200 based on MLPerf Training v4.1 benchmarks [2]
- A 800 GPU-hour H200 job costs $3,200 at $4/hr. B200 finishes the same job in 364 hours — total cost $2,000 despite the higher rate
- 405B parameter models need 4 H200s at FP8 vs 3 B200s — the saved fourth GPU also eliminates NVLink bandwidth overhead
- H200 has 2–4 week OEM availability; B200 lead times run 8–16 weeks for enterprise buyers today
H200 vs B200 spec comparison, MLPerf benchmarks, cloud pricing as of May 2026, and a worked cost comparison for LLM training and inference workloads.
In this article
H200 vs B200 SXM: Spec Gap, VRAM, and Architecture Differences
Both GPUs ship in SXM form factors with HBM3e memory. The H200 is the last Hopper-generation chip. The B200 is the first Blackwell-generation chip, built on a fundamentally new dual-die architecture. They are a full architectural generation apart.
H200 vs B200 Benchmarks: MLPerf Training and Inference Throughput Results
MLPerf Training v4.1 is the most reliable cross-GPU benchmark available. On GPT-3 175B pre-training, the B200 completed jobs in roughly 2x less time than H200. On LLaMA 70B LoRA fine-tuning, the speedup was 2.2x.[2]
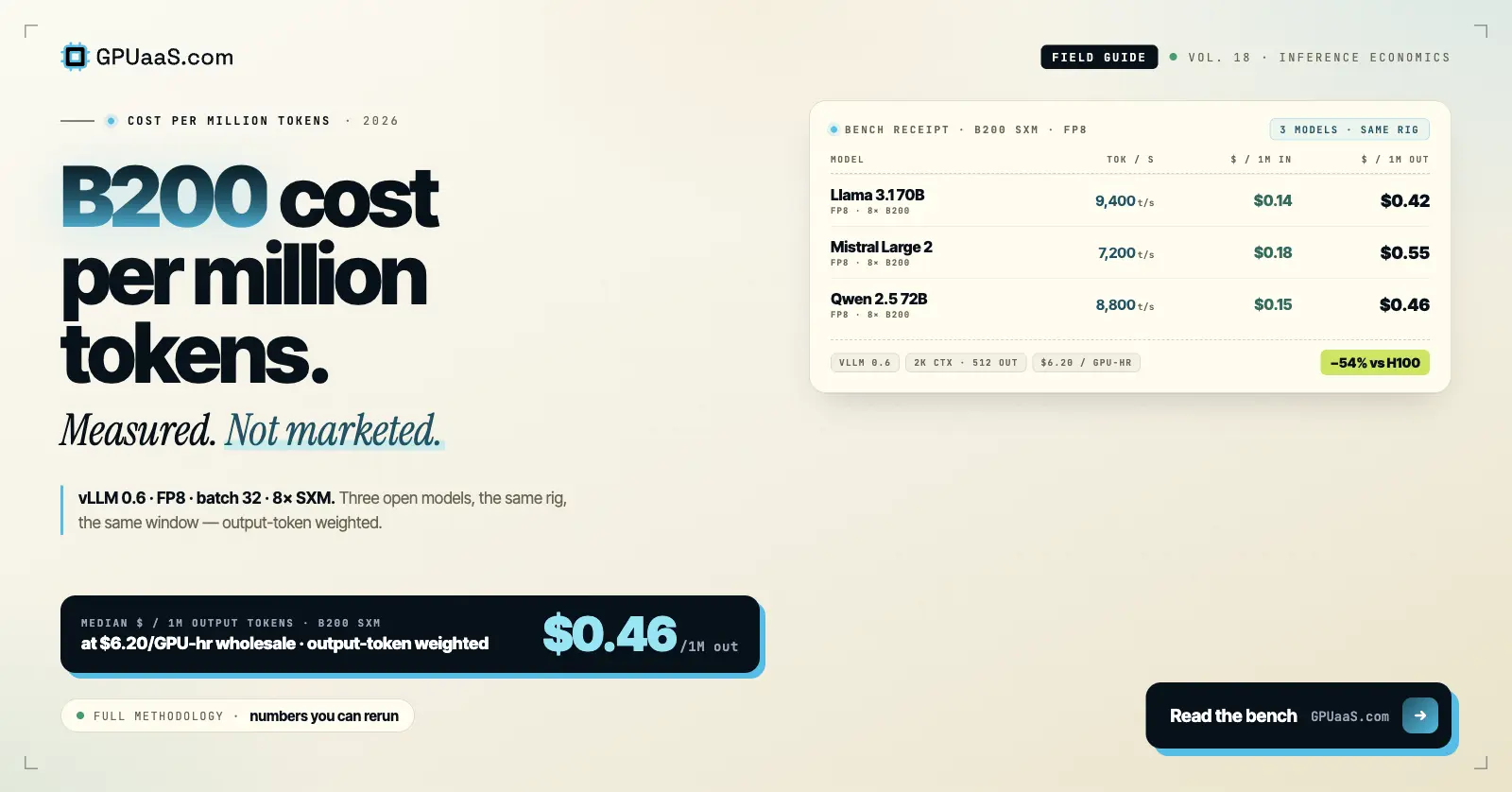
For inference, the gap is larger. SemiAnalysis InferenceX benchmarks show the B200 delivering roughly 3x lower cost-per-token than H200 for large models running in FP4. For checkpoint-friendly batch workloads on spot, B200 spot at $2.12/hr delivers approximately $0.15 per million tokens — making it the cost leader across GPU cloud options as of May 2026.[3]
H200 and B200 Cloud Pricing by Provider Tier as of May 2026
Pricing spans a wide range depending on provider tier, term, and billing model. Hyperscalers charge 2–3x more than wholesale providers for the same silicon. H200 on-demand has increased about 25% since May 2025, from $3.11 to $3.89/hr per GPU on average.[1]
H200 or B200: Decision Framework for AI Training and Inference Teams
- ✓Model fits in 141 GB VRAM at your precision target
- ✓Need capacity within 2 to 4 weeks, H200 has broader availability
- ✓MLOps stack is optimised for Hopper with no migration overhead
- ✓Training run under 3 months and cost per hour matters more than throughput
- ✓Short-term proof-of-concept where a lower rate reduces risk
- ✓Training models above 70B parameters where B200 memory reduces GPU count
- ✓Inference cost per token is the primary metric and B200 FP4 wins
- ✓Planning 6+ months of training where throughput advantage compounds
- ✓Starting fresh without legacy Hopper tooling to migrate
- ✓Frontier model training where B200 is built for the job
H200 vs B200 Worked Cost Comparison for 70B LLM Fine-Tuning Jobs
Take a 70B parameter LLM fine-tuning run that takes 800 GPU-hours on H200. At wholesale on-demand rates:
- H200 at $4/hr: 800 hours × $4 = $3,200
- B200 at $5.50/hr, 2.2× faster: 364 hours × $5.50 = $2,000
The B200 costs $1,200 less despite the higher hourly rate, because it finishes faster. Browse H200 cluster availability and B200 cluster availability. See also: reserved vs on-demand pricing and B200 availability and lead times Q2 2026.
Last reviewed: May 19, 2026. Pricing from [1] getdeploying.com H200 (28 providers tracked) and [3] Spheron (May 14, 2026). Benchmarks from [2] Spheron B200 guide (MLPerf Training v4.1 and SemiAnalysis InferenceX). Find H200 or B200 clusters through GPUaaS.com.