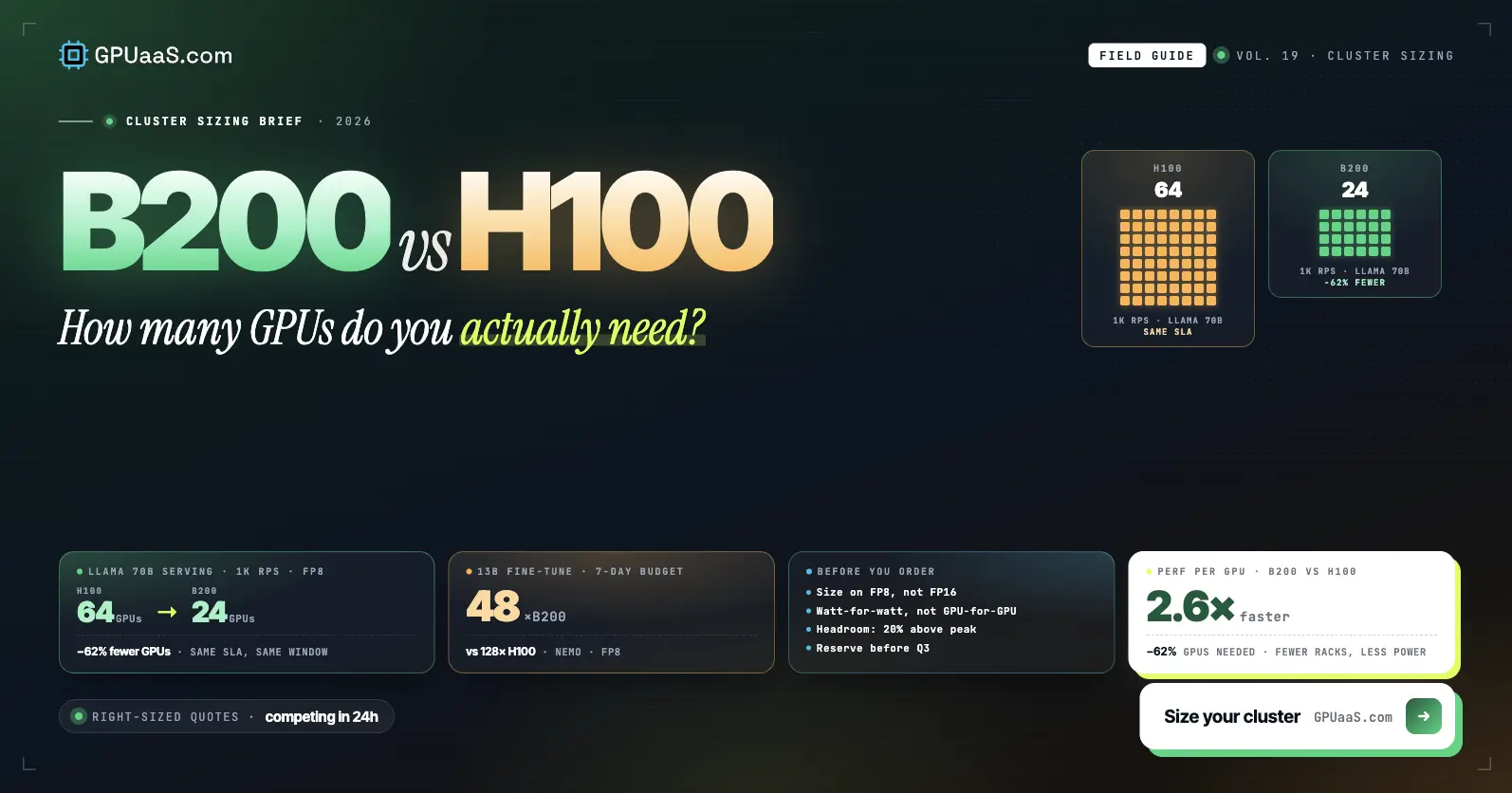
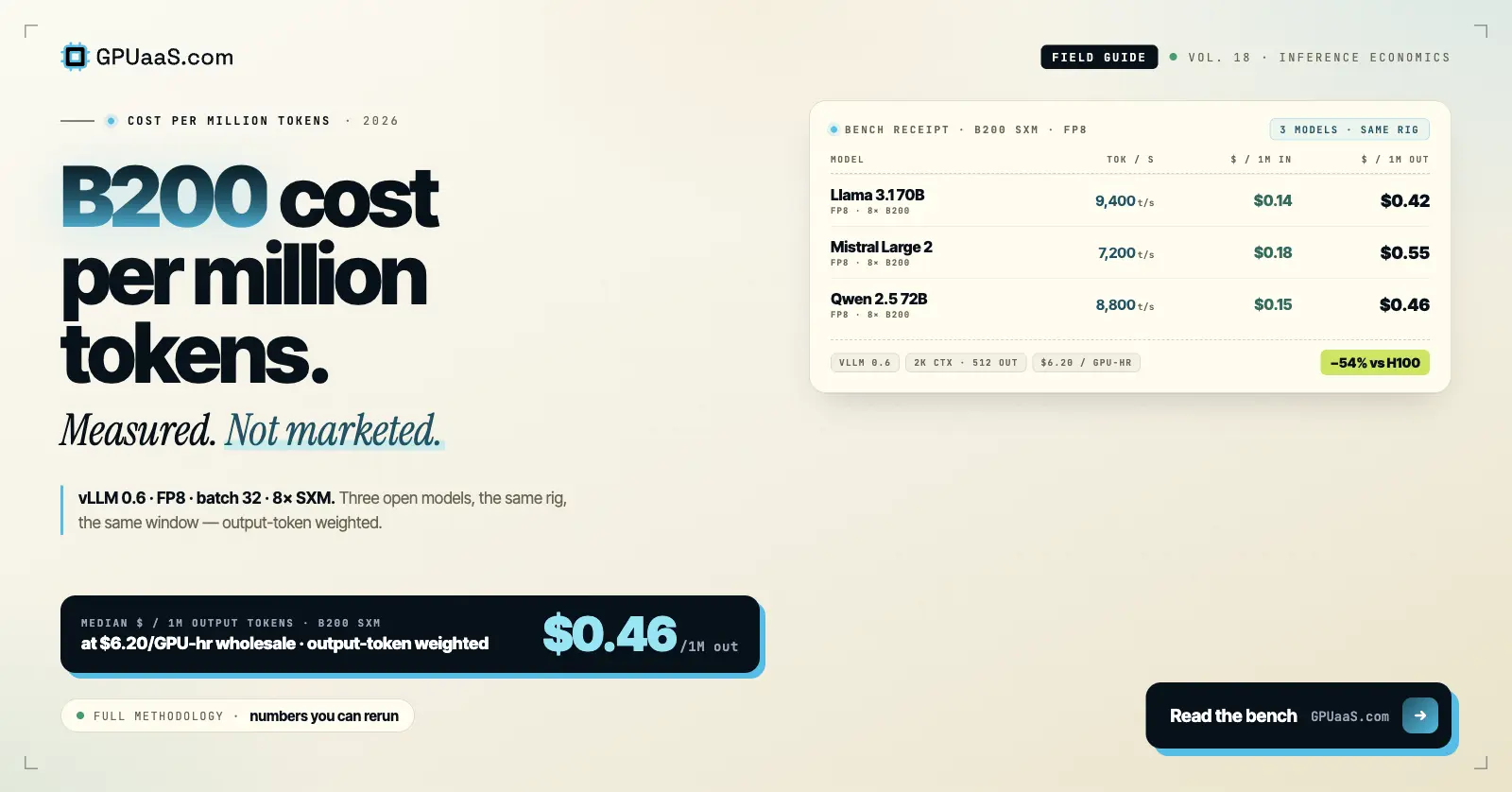
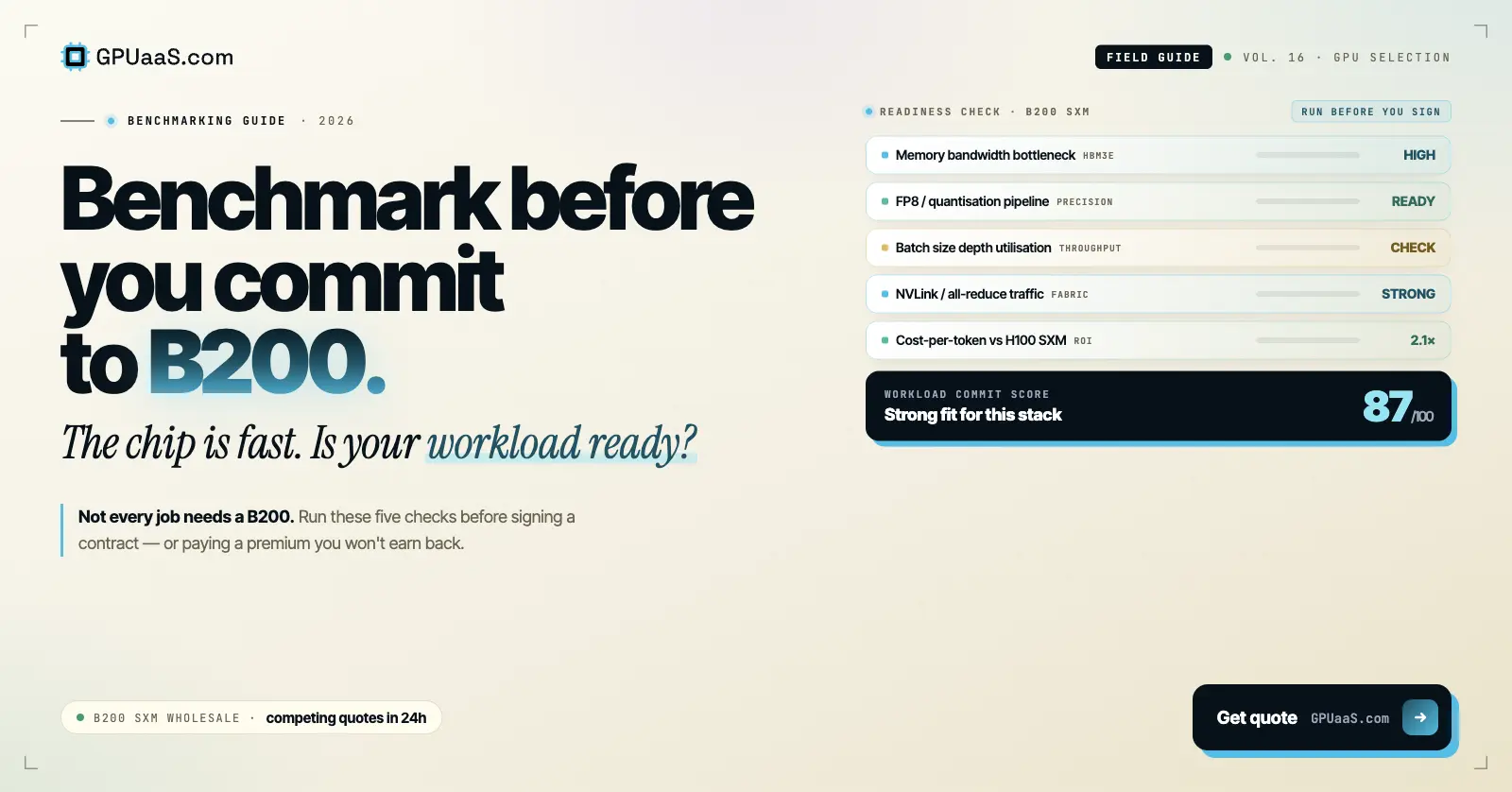
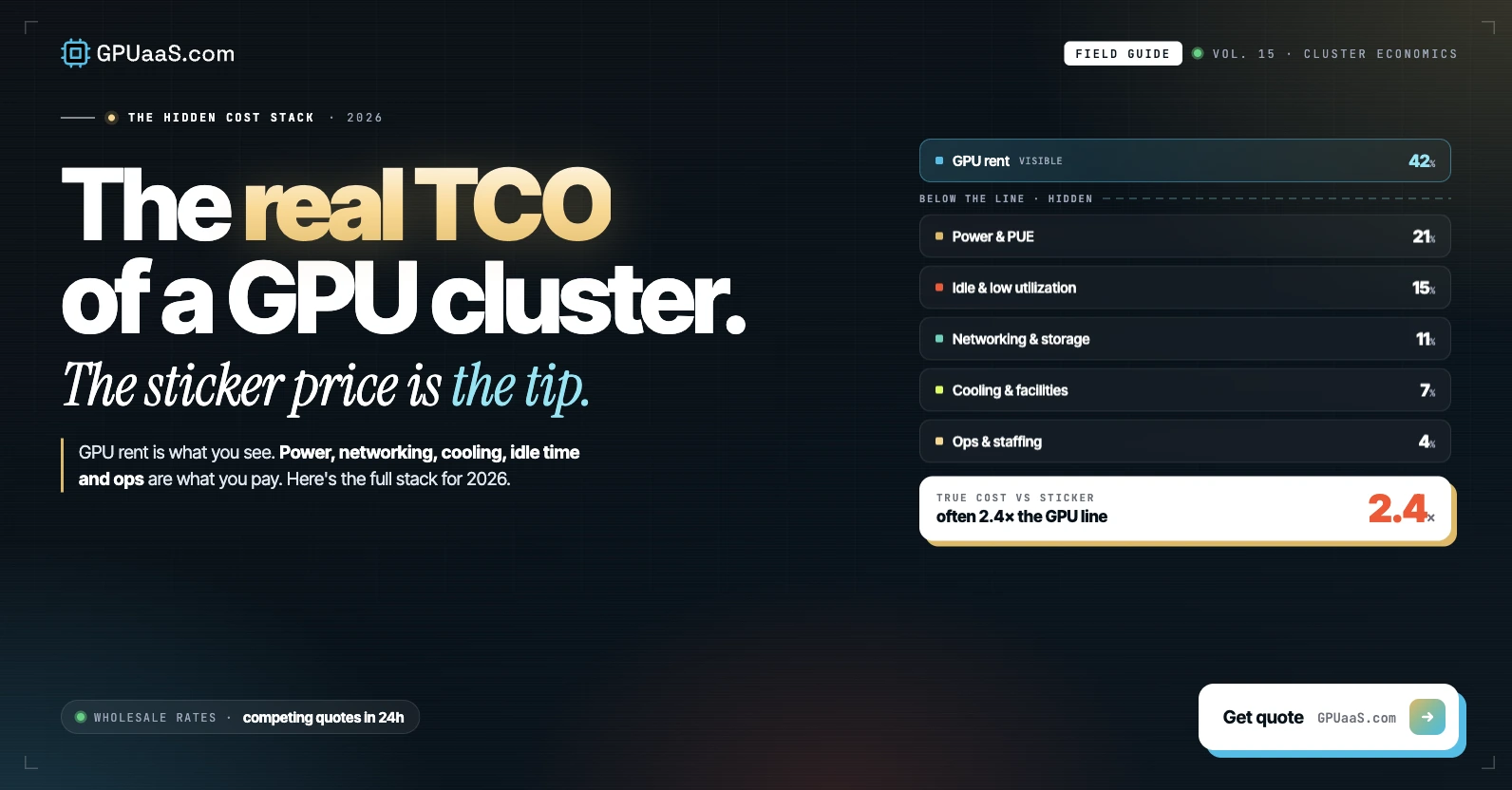
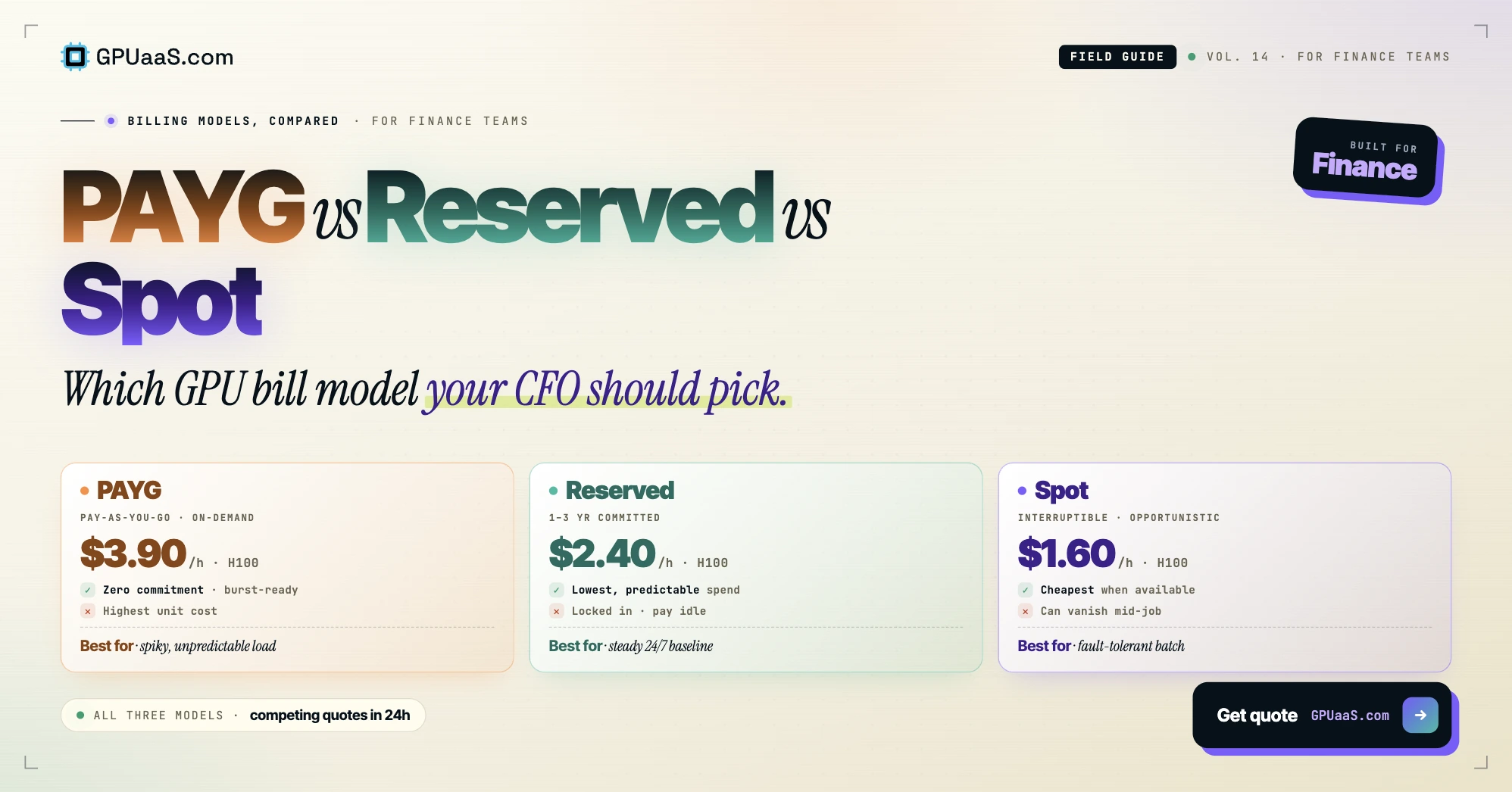
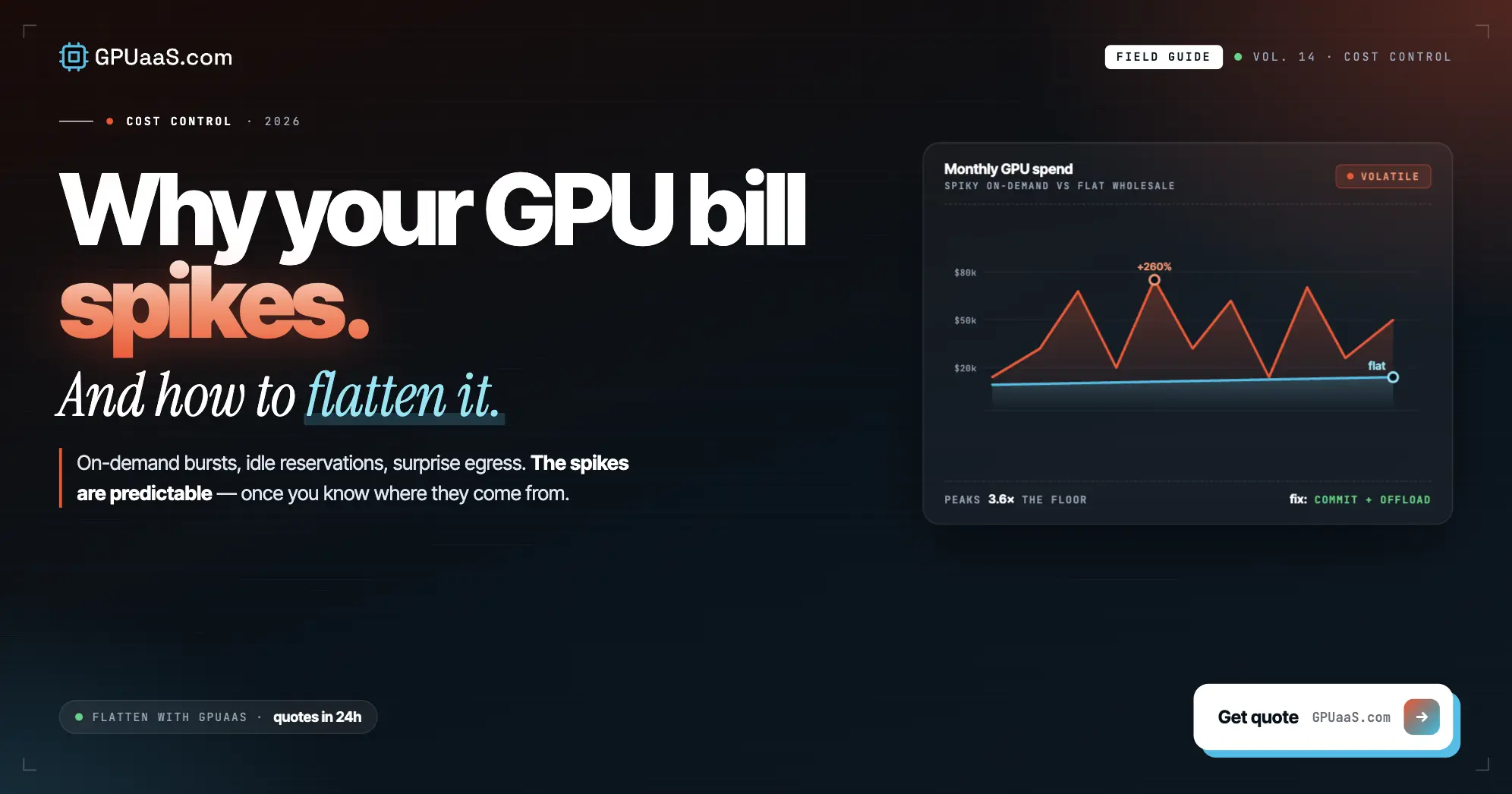
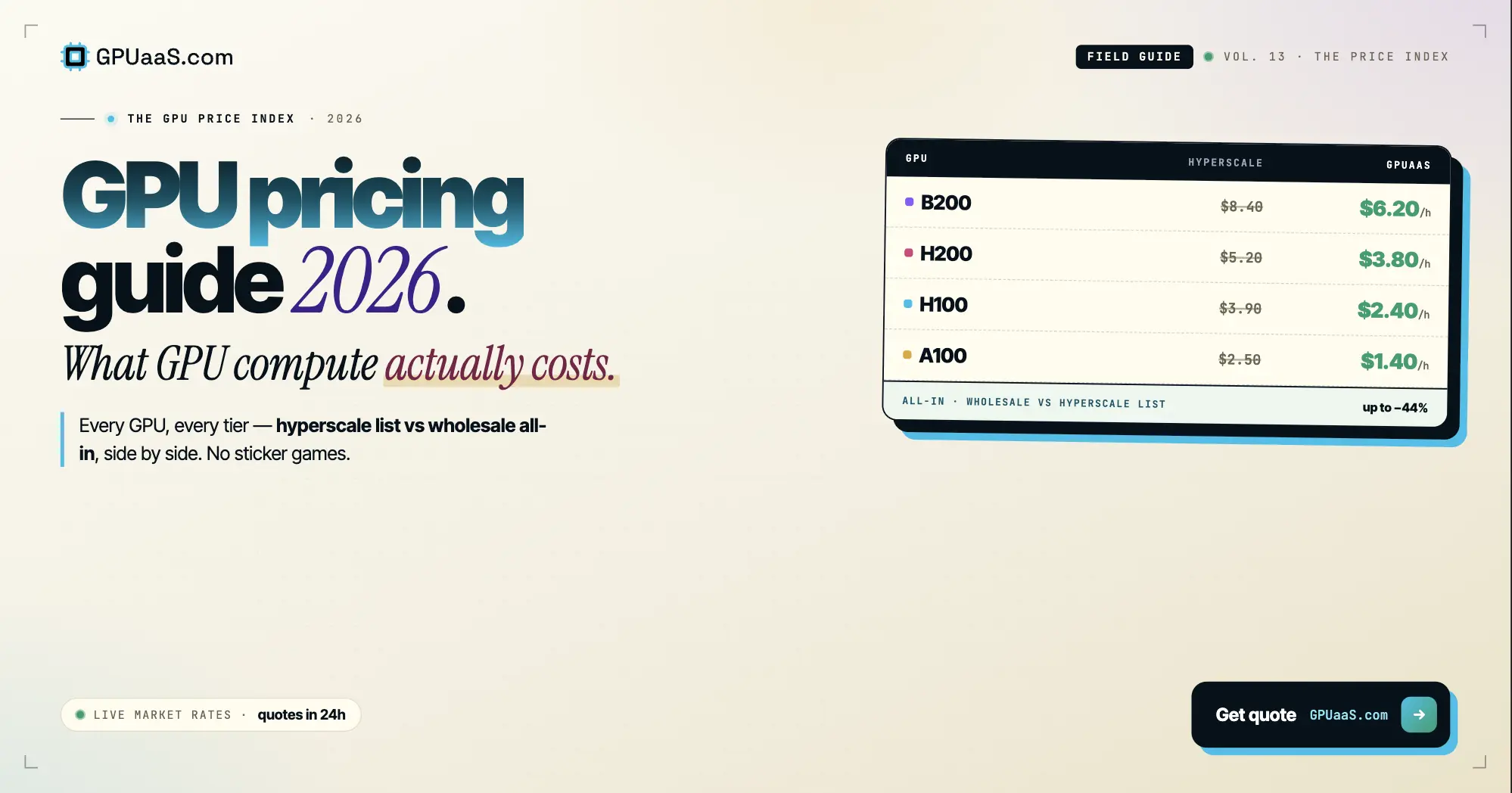
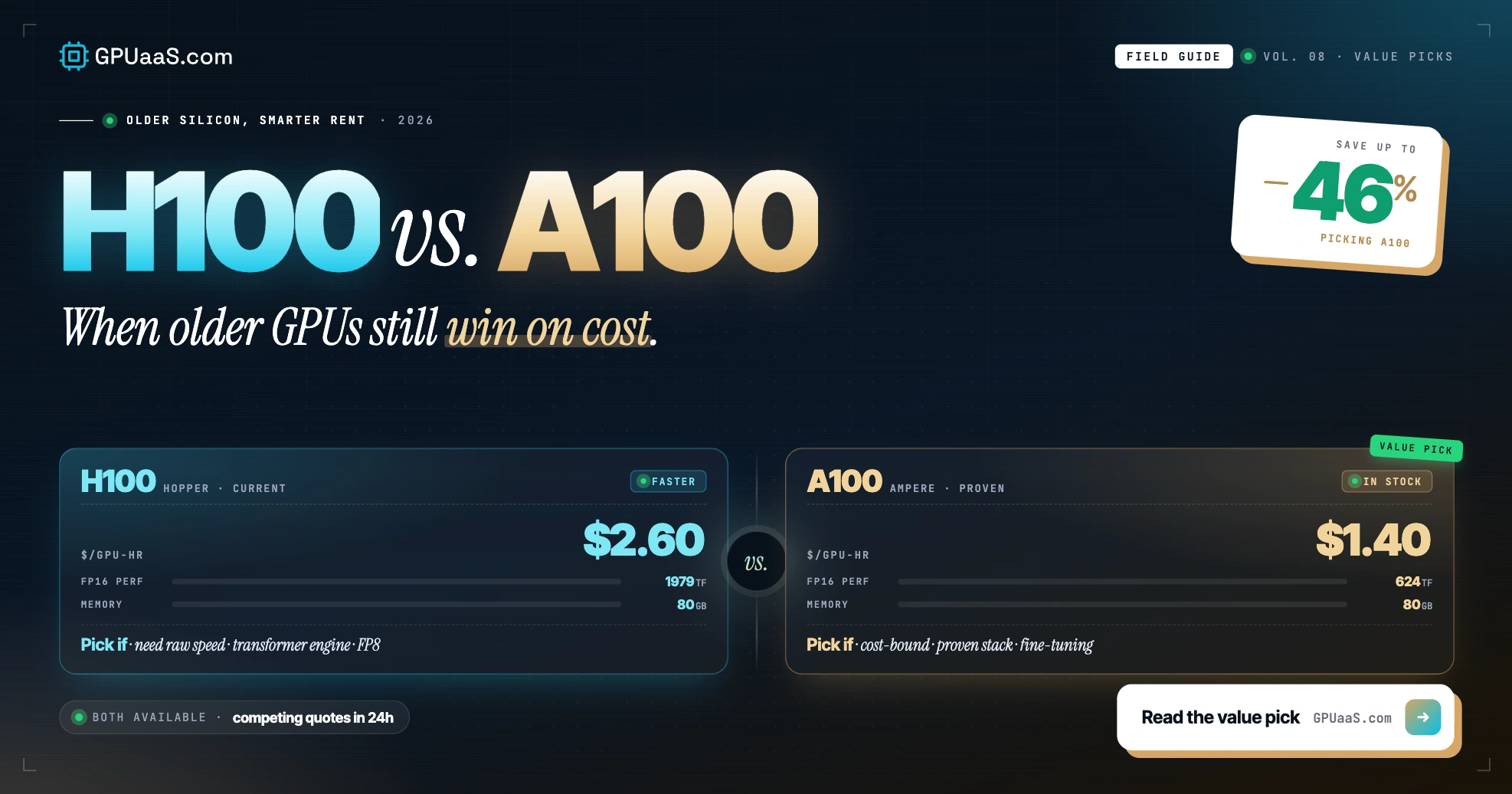
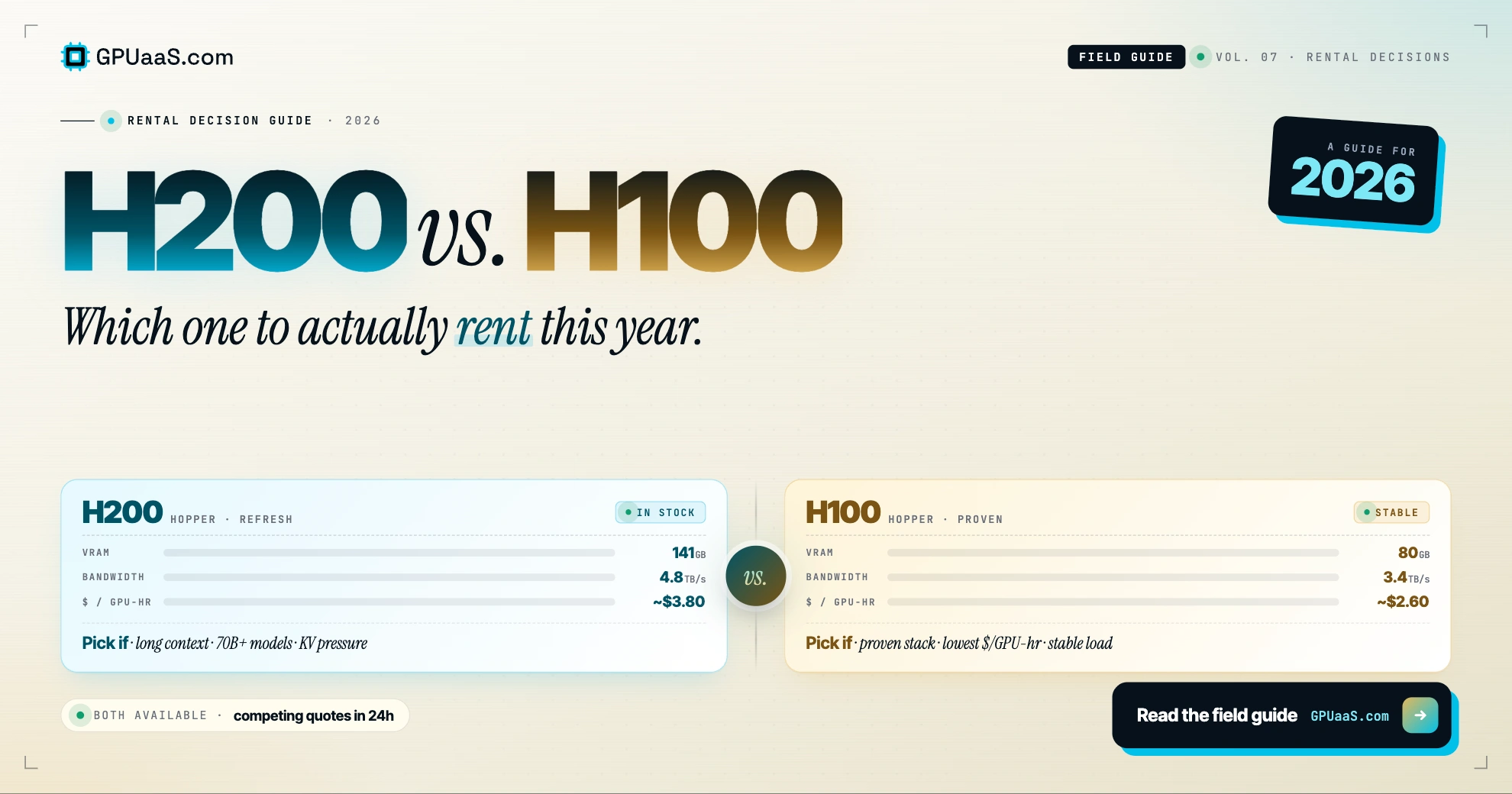
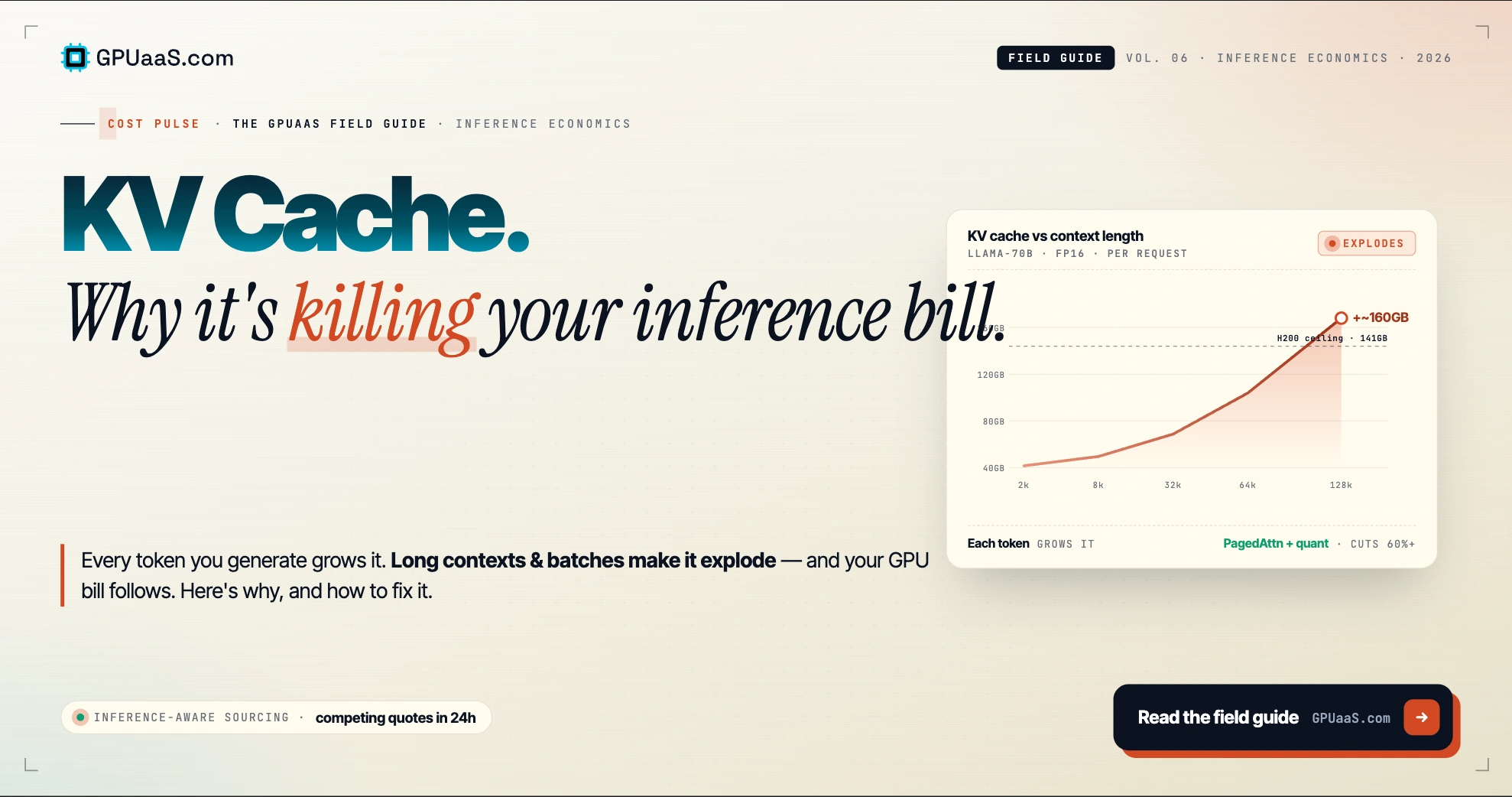
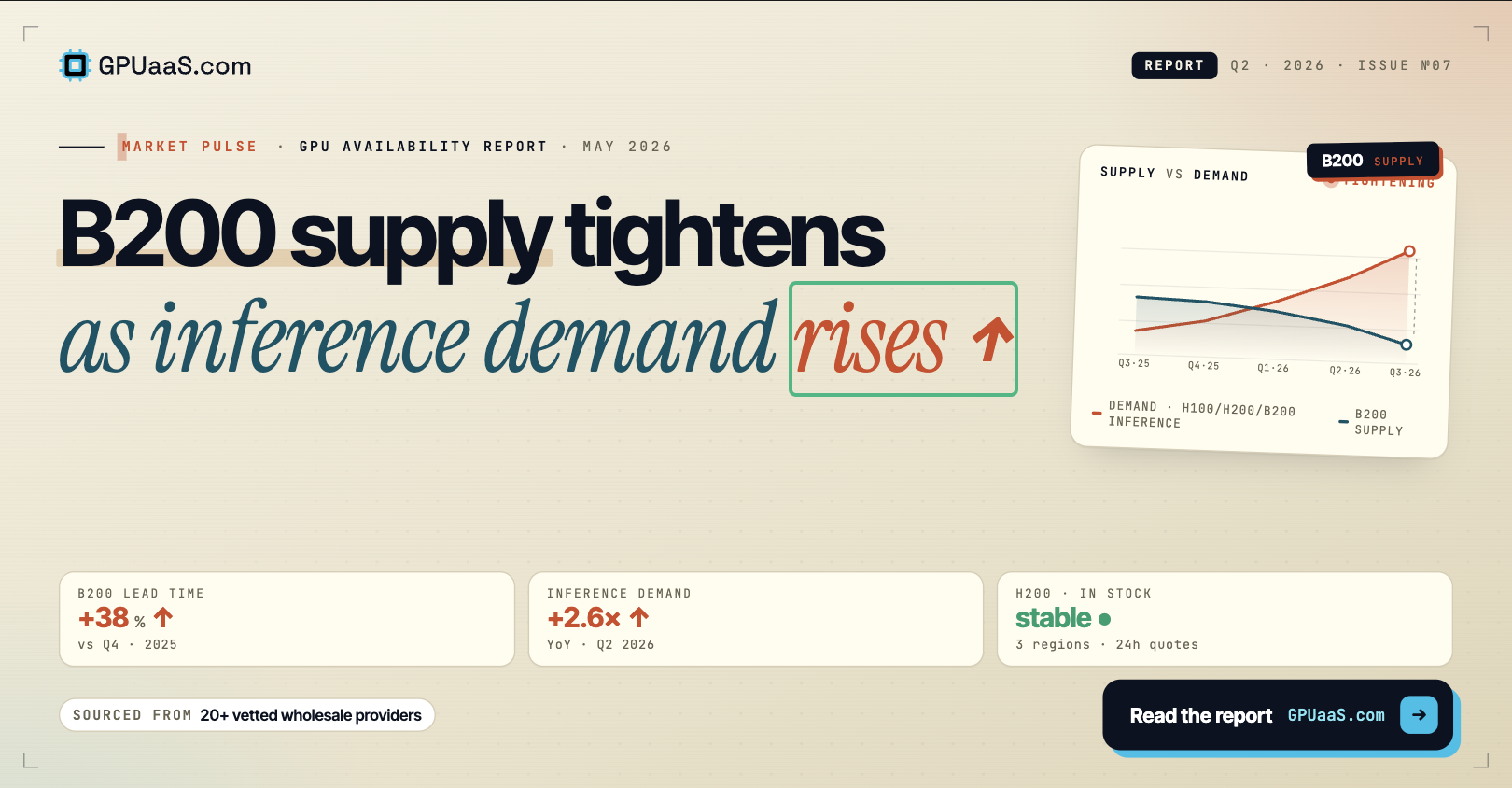
Practical analysis on GPU procurement, AI infrastructure, and wholesale compute markets — for teams running serious workloads.
Get quotes from 20+ vetted providers within 24 hours — B200, H200, H100, A100. No lock-in.
GPUaaS.com connects enterprises with vetted GPU providers for large-scale compute at up to 30% lower cost than hyperscalers.