++ NEW ++ NVIDIA B200 (EU) · H200 (US) · RTX 6000 Pro (US) · Get a quote →
Blog ▸ Nobody Tells You How the GPU Market Actually Works
GPU Infrastructure
The same H100 costs anywhere from $1.49 to $6.98 per hour. Most inventory is pre-sold before it reaches on-demand pools. And 80% of AI infrastructure spend now goes to inference, not training. Here is how the GPU market actually works.
Nobody Tells You How the GPU Market Actually Works
GPUaaS.com Team
GPU Market Intelligence
June 26, 2026
A team we know spent three weeks getting quotes for H100 capacity. They found a rate they liked, signed, and got their first invoice. The number was 38% higher than the rate they had negotiated. Nobody had lied to them. The egress fees, the persistent storage, the networking adder. It was all in the contract. They just had not known to look for it.
Key takeaways
H100 pricing spans a 4.7x range across providers in 2026: $1.49/hr spot marketplace to $6.98/hr Azure on-demand. Same GPU, different contract structure (GPUnex, 2026)
Most H100 and B200 capacity is pre-sold on 1 to 3 year contracts before it ever reaches an on-demand pool. What you see on a pricing page is what was left over
Inference now accounts for roughly 80% of AI infrastructure budgets. Per-token cost has fallen about 1,000x in three years. Total spend keeps going up because usage grows faster than price drops (GPUnex, 2026)
AWS cut H100 pricing by 44% in mid-2025. Teams on long reserved contracts signed at 2024 rates ended up paying more than customers on new on-demand pricing
Egress fees, idle bundled CPU and RAM, persistent storage, and region multipliers routinely add 20 to 40% on top of the advertised hourly rate on hyperscaler contracts
Most enterprise buyers approach GPU procurement the same way they approach buying servers or storage. They compare hourly rates, pick the provider with the best number, and sign something. That framework works fine for infrastructure markets with predictable pricing and standardized bundling. The GPU market in 2026 has neither.
How the market actually works is not complicated. It just takes a while to learn, and most teams learn it on their second or third contract, after the first invoice surprise.
◆ THE PRICING PAGE PROBLEM
What you are actually buying when you rent a GPU
When AWS lists the p5.48xlarge at $55.04 per hour, that rate covers eight H100 SXM5 GPUs. Divide by eight and you get $6.88 per GPU per hour. That is the number that goes into the procurement model.
What the $55.04 actually includes: eight H100 GPUs, 192 vCPUs, 2TB of RAM, 30TB of NVMe storage, and an elastic networking fabric. If you are running LLM inference, the GPUs are saturated and most of the rest sits idle. You pay for all of it.
Then come the charges that do not appear on the pricing page at all. Egress is $0.08 to $0.12 per GB on most hyperscalers. Moving a 100GB model checkpoint out of AWS is $8 to $12 on top of compute. Teams doing regular checkpoint syncs or serving across regions can end up with egress charges that rival their GPU bill. Persistent storage is billed separately at $0.10 to $0.30 per GB per month. Running in Europe or Asia adds a 10 to 30% regional premium.
Cast AI tracks GPU pricing across providers using live API feeds and telemetry from millions of scheduling events. Their read on the market: GPU prices follow hype and scarcity, not logic. The number on the pricing page and the number on the invoice are rarely the same.
The spread on H100 pricing in 2026 is 4.7x across provider types: $1.49 per hour on spot marketplace instances, $6.98 on Azure on-demand. Same GPU. The difference is how the hardware is bundled, where it sits in the supply chain, and what kind of contract you are on.
◆ HOW GPU INVENTORY ACTUALLY WORKS
The on-demand pool is not the whole market
Most buyers assume GPU capacity works like general cloud compute: there is a pool, you request from the pool, you get capacity or you wait a bit. That model stopped being accurate sometime in 2024.
The bulk of H100, H200, and B200 inventory gets sold on 1 to 3 year reserved contracts before it is deployed, sometimes before the hardware ships. Cast AI's GPU price report says it directly: most H100s and B200s are already pre-sold, tied to financial commitments spanning one to three years. What reaches the on-demand pool is whatever those contracts did not absorb.
This has a few practical effects. On-demand inventory is smaller and less predictable than buyers expect. Spot pricing spikes during demand windows because spot draws from the same constrained pool. And availability varies dramatically by region. AWS might show H100 capacity in us-east-1 with nothing in us-west-2. Cast AI found a 45% availability gap between two GCP availability zones in the same region in June 2025.
If you are trying to provision GPU capacity through a standard on-demand channel for the first time, you are competing for residual inventory. The main market cleared before you got there.
4.7x
pricing spread for the same H100 hardware in 2026: from $1.49/hr spot to $6.98/hr hyperscaler on-demand. Contract structure explains most of it.
GPUnex Cloud GPU Pricing Comparison, 2026
GPUaaS.com works differently. Buyers submit requirements and receive quotes from vetted providers within 24 hours, including clusters that are not publicly listed anywhere. That visibility into pre-market inventory is worth more in 2026 than it was two years ago.
◆ SPOT PRICING
When spot works and when it doesn't
The AWS H100 spot price dropped 88% between January 2024 and September 2025: from $105.20 to $12.16 for an 8-GPU instance. That is an 8.65x cost efficiency gain in 20 months. For batch training jobs with checkpointing, spot is genuinely the cheapest path to GPU compute available.
The problem is using spot as a planning input. Cast AI tracks this: spot pricing for GPU instances has become unreliable for teams trying to build predictable cost models. Enterprises that ran development workloads on spot in 2024 have found the same instances unavailable at any price during high-demand windows in 2026.
Spot markets exist for supply-demand balancing, not cost stability. A cluster priced at $12.16 in September 2025 may simply not appear during a demand spike. Teams that built workflows around those rates and then hit a demand window had to pay on-demand prices or wait. Neither option works when something is in production.
Spot is the right choice for fault-tolerant batch training, offline inference, and anything that checkpoints and resumes. It is not a reliable foundation for production inference or any workload with a fixed deadline. For the decision framework, the reserved vs on-demand GPU guide covers it in full.
◆ WHERE THE BUDGET GOES
Inference ate the training budget and nobody noticed until the invoice arrived
Two years ago AI infrastructure spend was training-heavy. Big model runs were expensive, visible, and approved upfront. Inference costs were smaller and more predictable.
That has flipped. Inference now accounts for roughly 80% of AI infrastructure budgets according to GPUnex 2026 analysis, up from a training-dominated split just two years earlier. Per-token inference cost has fallen about 1,000x in three years, from around $20 per million tokens in early 2024 to under $0.40 by early 2026. Total spend keeps climbing because usage grows faster than unit cost falls.
Finance teams get surprised by this because inference spend does not arrive as one big line item. It accumulates as more AI features ship, as more users interact with products, as agent workflows start making more API calls per task. By the time anyone notices the GPU bill has tripled, the workload driving it has been running for months.
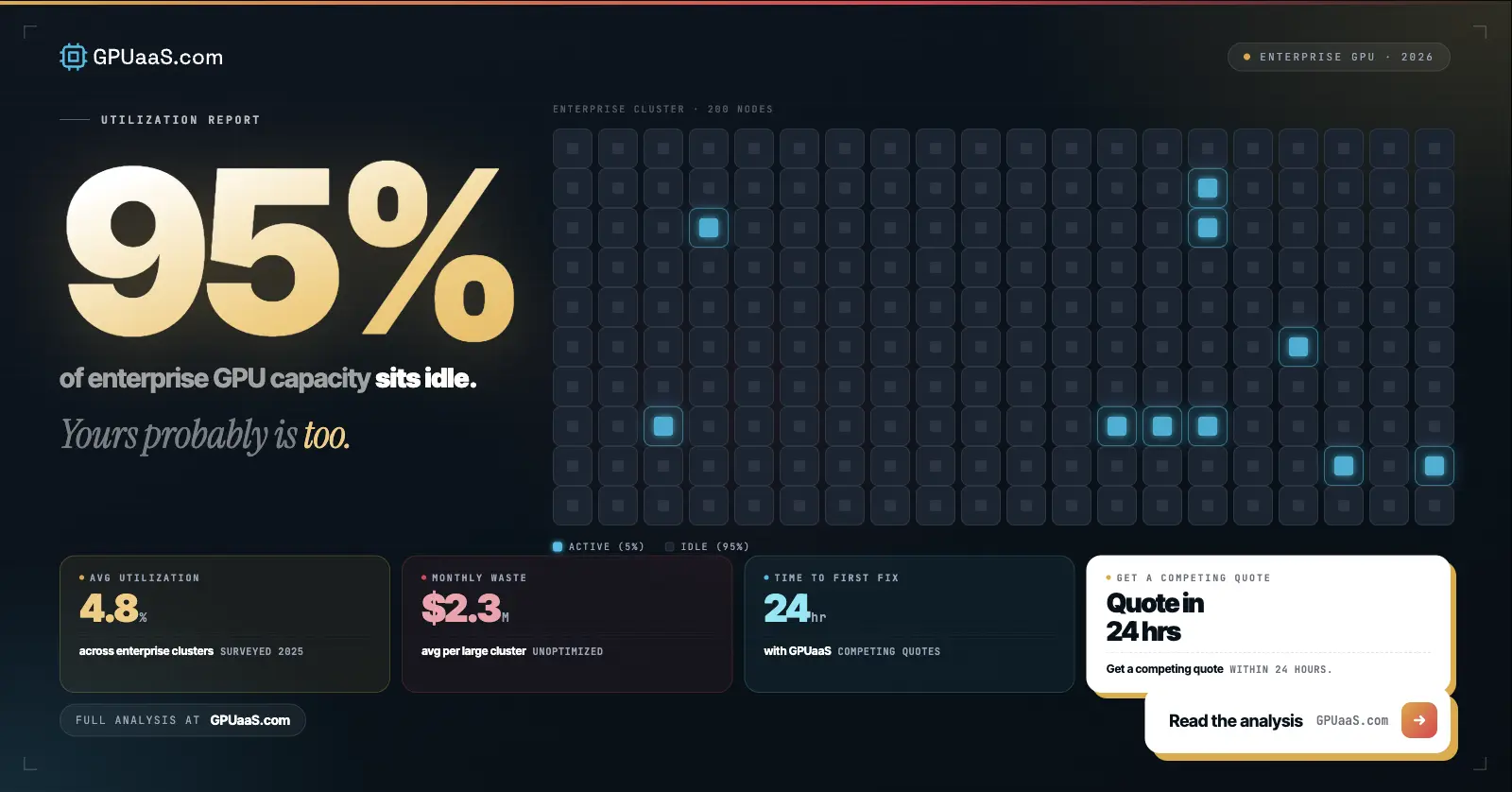
Cast AI 2026 data shows average GPU utilization across 23,000 production clusters at 5%. At that utilization rate, a $6.88/GPU/hour instance has an effective cost of $137.60 per hour of actual compute work. A cluster running at 20% utilization is paying 5x the real compute cost. Most teams have no visibility into their actual utilization until they specifically go looking for it.
There is a common assumption that teams who locked in GPU capacity early got the better deal. Sometimes that is true. AWS cut H100 pricing by roughly 44% in mid-2025, one of the sharpest GPU price drops in cloud history. Teams that had signed 1 or 3-year reserved contracts at 2024 rates ended up paying more than new on-demand customers for exactly the same hardware. The commitment that felt like cost certainty became a cost liability when the market moved.
This is not an argument against reserved contracts. For stable inference workloads with predictable demand, 12 to 24 month commitments still save 30 to 40% over on-demand rates. The point is that a reserved contract is a bet on price stability. In a market where a single pricing action can move rates 44%, that bet needs more analysis than most teams apply before signing.
The teams navigating this well in 2026 match commitment length to how confident they are about their workload demand. Short contracts while a workload is still being validated. Longer commitments once inference demand has stabilized and the pattern is clear. And provider relationships across more than one source, so when one rate becomes uncompetitive there is somewhere to go.
GPUaaS.com does not require multi-year commitments upfront. Pricing reflects what the market actually is rather than a hyperscaler retail markup. For the current rate picture across GPU models, the GPU pricing guide has the numbers. For H100 specifically, the H100 cost per hour analysis goes deeper. And for how wholesale rates compare to hyperscaler pricing, the wholesale vs hyperscale breakdown explains the gap.
◆ WHAT TO ACTUALLY DO
Four things that change your GPU procurement outcomes
None of this is especially hard once you know it. The problem is most buyers do not know it until after the first contract.
Normalize to per-GPU-hour before comparing anything. Hyperscalers quote per instance. Purpose-built providers quote per GPU. Google Cloud quotes per VM. These are not the same number and comparing them directly will mislead you. The 4.7x H100 pricing spread is invisible until you put everything on the same basis.
Model egress and storage before you sign. Take your expected monthly data transfer volume, multiply by $0.08 to $0.12 per GB. Add persistent storage at your dataset and checkpoint sizes. Apply any regional multiplier. This usually adds 20 to 40% to the headline rate. Do it before the contract, not after the invoice.
Match your commitment length to your utilization certainty. If you know what your inference workload looks like in 18 months, commit for 18 months. If you are still in validation, sign something short and extend when the pattern is clear. The 40% discount on a 3-year term is only worth it if the workload is actually stable for 3 years.
Get visibility into inventory that has not been publicly listed yet. On-demand pools are the overflow after reserved contracts have been filled. GPUaaS.com surfaces clusters from vetted providers before they hit public listing, including capacity not visible through hyperscaler portals. Buyers who submit requirements receive quotes within 24 hours. That window is often the difference between securing a cluster this month and joining a waitlist.
See what GPU capacity is available right now.
NVIDIA B200, H200, H100, A100, RTX Pro 6000. North America, EU, MEA, APAC. No buyer fees. Also on packet.ai for self-serve access.
Three things drive the 4.7x spread. Contract structure: spot draws from volatile overflow pools; hyperscaler on-demand draws from a constrained but more stable pool at a markup; purpose-built providers with direct hardware relationships can price closer to cost. Bundling: hyperscalers quote per instance and include CPU, RAM, and storage you may not need; purpose-built providers quote per GPU only. And supply chain position: where the hardware sits relative to the reserved contract layer determines what you are actually competing for.
Egress at $0.08 to $0.12 per GB, persistent storage at $0.10 to $0.30 per GB per month, idle CPU and RAM bundled into instance pricing regardless of GPU utilization, 10 to 30% regional multipliers for non-US deployments, and per-hour billing minimums that round up short jobs. In combination these typically add 20 to 40% to the headline GPU rate on hyperscaler contracts. See the GPU quote hidden costs breakdown for the full picture.
No. Spot markets are built for supply-demand balancing, not cost predictability. During high-demand periods H100 spot instances can be simply unavailable at any price. Spot is the right choice for fault-tolerant batch training and any job that checkpoints and resumes. For production inference or anything with a deadline, on-demand or reserved capacity is the correct structure.
Usually one of three things. Egress and storage charges that were not modeled before signing. Low GPU utilization: Cast AI data puts average production cluster utilization at 5%, which means the effective cost per unit of real compute work is 20x the headline rate. Or inference workload growth that nobody tracked: inference now accounts for about 80% of AI infrastructure budgets and grows gradually as features ship, often without anyone monitoring the rate. The GPU bill spike guide covers the most common causes.
For stable inference workloads with predictable demand, 12 to 24 month reserved commitments save 30 to 40% over on-demand rates and are worth doing. The risk is that market prices can shift significantly during a long contract: AWS cut H100 pricing 44% in mid-2025, which put teams on older reserved contracts above new on-demand customers for the same hardware. Match commitment length to how confident you are about demand. The reserved vs on-demand GPU guide covers the decision in detail.
GPUaaS.com is a matchmaking marketplace connecting enterprise buyers with vetted GPU infrastructure providers. Rates are around 30% below hyperscaler pricing for equivalent hardware because they reflect actual market rates rather than retail markup. GPUaaS.com surfaces inventory not visible through hyperscaler on-demand portals, including clusters from purpose-built providers who sourced hardware through direct relationships. Buyers submit requirements and receive quotes within 24 hours. No buyer fees.
Last reviewed: 27 June 2026. Pricing spread data from GPUnex Cloud GPU Pricing Comparison 2026. Spot pricing analysis from Cast AI GPU Price Report 2026. Inference budget share from GPUnex 2026 ML cost analysis. Hidden cost estimates from CloudZero GPU cloud pricing comparison. Browse current GPU cluster availability on GPUaaS.com.