++ NEW ++ NVIDIA B200 (EU) · H200 (US) · RTX 6000 Pro (US) · Get a quote →
Blog ▸ Why Your GPU Quote Doesn't Mean What You Think It Means
GPU Infrastructure
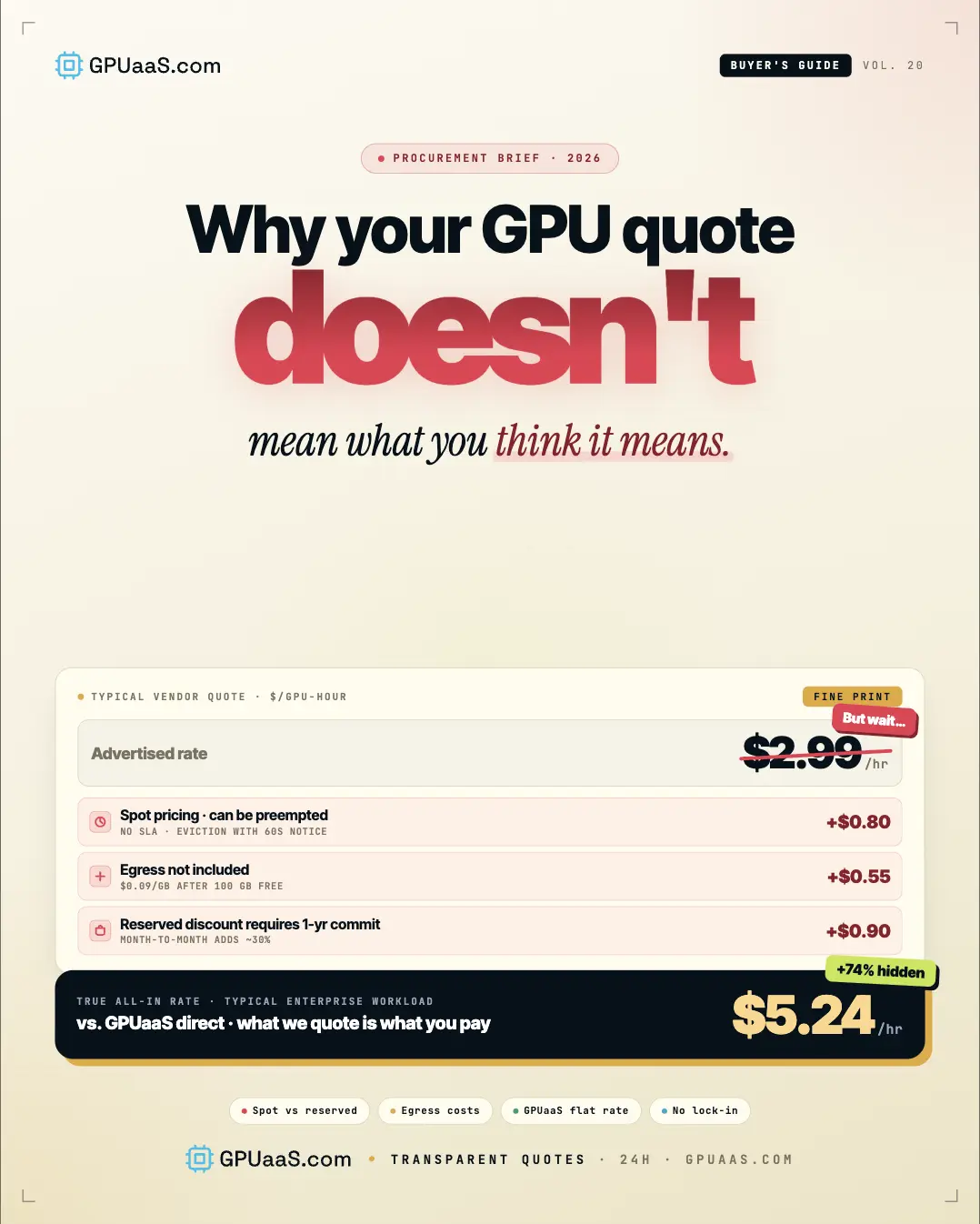
That H100 rate you were quoted includes 192 vCPUs, 2 TB of RAM, and 30 TB of storage you may not need. Here is what a GPU quote actually covers and what shows up later on the invoice.
Why Your GPU Quote Doesn't Mean What You Think It Means
GPUaaS.com Team
GPU Procurement
June 22, 2026
A GPU quote is not a GPU price. When a hyperscaler quotes you an H100 rate, that number bundles 192 vCPUs, 2 TB of RAM, 30 TB of local NVMe storage, elastic networking fabric, and platform overhead into a single line item. None of which appear separately on the quote you receive.
Key takeaways
AWS on-demand H100 rates run $6.88/GPU/hour normalized from a p5.48xlarge at $55.04/hour. That instance bundles 192 vCPUs and 2 TB RAM you may not need
Egress fees on hyperscalers run $0.08 to $0.12/GB. Moving a 100 GB model checkpoint out of AWS adds $8 to $12 on top of compute
Hidden charges including idle CPU, storage, and networking can inflate the real hyperscaler bill by 20 to 40% beyond the advertised rate
Purpose-built GPU infrastructure quotes per GPU-hour directly. The H100 rate is the H100 rate, not a normalized slice of a bundled instance
Through GPUaaS.com, H100 clusters start from approximately $2.50/GPU/hour, a significant gap from hyperscaler on-demand rates for identical silicon
GPU procurement usually starts the same way. Someone on the team pulls up a cloud provider pricing page, finds the H100 instance, divides by eight GPUs, and writes down a per-GPU number. That number goes into a spreadsheet. The spreadsheet drives the budget conversation. And then the monthly invoice arrives with line items nobody planned for.
This is not a billing accident. It is how large cloud platforms are structured. Understanding what a GPU quote actually contains is the starting point for any serious infrastructure decision in 2026. For a broader view of how GPU pricing works across models and contract types, the GPU pricing guide for 2026 covers the full picture.
◆ THE QUOTE
What hyperscalers actually bundle into a GPU quote
Take the AWS p5.48xlarge as a concrete example. The instance lists at $55.04 per hour in us-east-1. Divide by eight GPUs and you get $6.88 per H100 per hour. That is the number most teams write down.
What that number actually covers: eight NVIDIA H100 SXM5 GPUs, 192 vCPUs, 2,048 GB of system RAM, 30 TB of local NVMe storage, second-generation Elastic Fabric Adapter networking, and the managed platform stack sitting on top of all of it. If you are running a 70B parameter inference workload, you are using eight GPUs intensively and leaving most of the other resources largely idle.
Azure's NC H100 v5 instance runs around $6.98 per GPU on-demand. The ND H100 v5 configuration can reach $12 per GPU-hour depending on configuration. Oracle Cloud bills H100 bare-metal at a flat $10 per GPU-hour. Three different quotes for the same GPU chip, priced using three different bundling philosophies, and none of them tell you what the GPU actually costs to run.
Bare metal, OCI networking, block storage billed separately
GPUaaS.com
H100 SXM5 cluster
from ~$2.50
GPU compute only, no bundled services, no retail markup
Rates as of June 2026. Hyperscaler rates from public pricing pages. GPUaaS.com rates are indicative and quote-based; actual pricing depends on cluster size, region, and contract length.
◆ HIDDEN COSTS
Four hidden costs that inflate every hyperscaler GPU bill
The bundled instance rate is only the starting point. Four categories of additional charges reliably appear on hyperscaler GPU bills, and none of them show up in the pricing page headline.
Egress fees. AWS, Azure, and GCP charge between $0.08 and $0.12 per GB for outbound data transfer after the free tier. A 100 GB model checkpoint downloaded after a training run costs $8 to $12 in egress fees on top of the GPU hours. At scale, teams syncing checkpoints or running multi-region inference can find egress matching or exceeding their compute bill.
Idle CPU and RAM. The p5.48xlarge gives you 192 vCPUs whether your workload uses them or not. A vLLM inference server running a 70B model saturates the GPUs and uses a fraction of the bundled CPU capacity. You are paying for the idle cores regardless.
Storage charges. Temporary instance storage does not persist between sessions. Persistent storage for datasets and model checkpoints is billed separately, typically at $0.10 to $0.30 per GB per month on hyperscalers. A moderately large training dataset and a few checkpoint saves can add hundreds of dollars monthly.
Region multipliers. Non-US regions carry a 10 to 30% premium on most hyperscaler GPU instance types. A team running inference in Europe or Southeast Asia pays more than the headline US rate, and that premium is not prominently disclosed.
According to third-party infrastructure research, these hidden charges add 20 to 40% on top of the advertised GPU hourly rate. A quote that looks like $6.88/GPU/hour can land as $8.50 to $9.65 by the time the invoice closes. For a deeper look at where GPU bills spike unexpectedly, see why your GPU bill spikes and how to flatten it.
◆ BILLING MODELS
Why the billing model matters as much as the rate
Even before hidden charges, the billing model itself shapes what you pay. The same GPU hardware runs at three materially different rates depending on how you contract for it.
On-demand is the most expensive and most flexible. You pay the published rate with no commitment. It makes sense for development, validation, and short-duration jobs.
Reserved or committed pricing lowers the per-hour rate in exchange for a defined term, typically three to twelve months. On hyperscalers, one-year commitments reduce on-demand rates by 30 to 40%. On purpose-built GPU infrastructure, committed terms deliver better rates without multi-year lock-in.
Spot pricing offers the lowest headline rate, sometimes 50 to 80% below on-demand, but instances can be interrupted when demand spikes. For production inference that cannot tolerate interruption, spot is not a reliable cost reduction strategy.
⚡ Note
Hyperscaler spot pricing for H100 can look competitive on a pricing page but availability is inconsistent. A long training run interrupted mid-job without checkpointing loses all progress and still incurs the hours billed before termination.
For a detailed breakdown of when each model makes sense, the reserved vs on-demand GPU guide covers the decision framework in full.
◆ UTILISATION
GPU utilisation: the number nobody puts in the budget
Average GPU utilisation across production clusters sits at approximately 5%, according to Cast AI's 2026 State of Kubernetes Optimization report. At 5% utilisation, the effective cost per unit of useful compute is twenty times the headline rate. A GPU running at $6.88/hour with 5% utilisation has an effective cost of $137.60 per hour of actual compute work performed.
This is not a hyperscaler-specific problem, but it compounds significantly on bundled instances. When you are paying for 192 idle vCPUs alongside eight partially-loaded GPUs, the utilisation math gets worse. Improving GPU utilisation through better batching, right-sizing cluster configurations, and matching GPU memory to model size is the highest return optimisation available to most AI infrastructure teams.
For a concrete look at how these costs add up across a full GPU cluster lifecycle, the real TCO of a GPU cluster in 2026 breaks down every cost category with worked examples.
◆ THE REAL RATE
What a GPU-only rate actually looks like
Purpose-built GPU infrastructure quotes per GPU-hour directly. There is no instance bundling, no derived math, no normalisation required. The rate you see is the rate for the GPU.
GPUaaS.com connects enterprise buyers to vetted GPU infrastructure providers and quotes H100 clusters from approximately $2.50/GPU/hour, H200 clusters from approximately $3.00/GPU/hour, and B200 clusters from approximately $4.50/GPU/hour. These are contract-based rates; actual pricing depends on cluster size, region, and commitment length. Quotes arrive within 24 hours of submitting requirements.
~2.7x
the gap between AWS on-demand H100 rates and GPUaaS.com indicative H100 rates for identical silicon, before egress and storage charges
Before committing to any GPU contract, four questions will tell you whether you are looking at the full cost or just the headline.
Is this a per-GPU rate or a per-instance rate? If it is per-instance, divide by the GPU count and ask what else is bundled in.
What are the egress fees? For any workload that moves data out of the provider environment (model downloads, checkpoint syncs, inference serving across regions), egress can be a significant line item that does not appear on the base quote.
How is storage billed? Temporary instance storage is typically included. Persistent storage is usually not. If your workflow requires persistent volumes for datasets or checkpoints, get the storage rate and model it into the monthly estimate.
Does the rate change by region? If your workload needs to run in the EU or APAC for latency or compliance reasons, confirm the regional rate before assuming the headline figure applies.
Get a transparent GPU quote within 24 hours.
H100, H200, B200, B300 clusters. No bundled services. No egress markup. No buyer fees.
Hyperscalers sell GPU instances as bundled products that include vCPUs, system RAM, storage, and networking alongside the GPU. The headline rate covers all of these, but the quote rarely explains the breakdown. Additional charges for data egress ($0.08 to $0.12/GB), persistent storage, and region multipliers then stack on top. Third-party research puts the real bill 20 to 40% above the advertised GPU rate once these are accounted for.
The AWS p5.48xlarge lists at $55.04 per hour on-demand in us-east-1, which normalises to approximately $6.88 per H100 GPU per hour. That is before egress, persistent storage, or support tier costs. One-year reserved pricing reduces this by around 30 to 40%, but requires upfront commitment. Spot pricing can bring the per-GPU rate below $4, but P5 spot availability is inconsistent for production use.
GPUaaS.com is a quote-based service, so rates depend on cluster size, region, and contract length. Indicative H100 SXM5 rates start from approximately $2.50 per GPU per hour. Quotes are provided within 24 hours of submitting requirements. There are no buyer fees at any stage. View current H100 cluster availability here.
On hyperscalers, egress fees are structural and apply to most outbound data transfers above the free tier. Purpose-built GPU infrastructure providers often include bandwidth in the instance rate or charge flat rates significantly below hyperscaler egress pricing. Ask specifically whether egress is included and what the rate is for your expected monthly data transfer volume.
Directly and significantly. Average GPU utilisation across production clusters sits at approximately 5% according to Cast AI's 2026 data. At 5% utilisation on a $6.88/GPU/hour instance, the effective cost per hour of actual compute work is approximately $137.60. Improving utilisation through better batching, right-sizing GPU memory to model requirements, and avoiding idle instances is typically the highest-return infrastructure optimisation available.
For workloads with predictable, sustained utilisation (production inference, ongoing training pipelines, stable research clusters), reserved pricing reduces the per-GPU rate by 30 to 40% compared to on-demand. The key question is whether your utilisation is consistent enough to justify the commitment. See the reserved vs on-demand GPU guide for the full framework.
The right GPU is the cheapest one your workload does not saturate. Running a 13B parameter model on an H200 with 141 GB of HBM3e means paying for memory headroom you are not using. If you are deciding between H200 and H100 tiers, the H200 vs H100 rental guide covers the decision in full. Running the same workload on an H100 with 80 GB of HBM3 is sufficient and cheaper. The H100 vs H200 vs B200 comparison covers the decision framework by workload type.