

GPU bills don't spike because your hourly rate is wrong. They spike because you're paying for 100% of a cluster that's running at 5% utilisation, provisioned on the wrong contract length, with egress and storage charges quietly compounding in the background. Stop hunting for GPU compute. GPUaaS.com gets you enterprise NVIDIA infrastructure at rates hyperscalers won't offer you, but the rate is only one part of what drives your bill.
- Average GPU utilisation across enterprise Kubernetes clusters is 5%, meaning teams pay for 20x more compute than they use (Cast AI, April 2026, 23,000 clusters measured)
- A 50 cent difference in GPU rate on an 80-GPU H100 cluster over 6 months compounds to $173,000 in either waste or savings
- AWS raised H200 Capacity Block prices 15% in January 2026, breaking a 20-year pattern of falling compute costs
- Egress and storage charges inflate hyperscaler GPU bills by 20 to 40% on top of the headline compute rate
- 89% of organisations now cite Kubernetes rightsizing as a top priority after GPU-heavy AI workloads blew through budgets (CloudBolt, March 2026)
- GPUaaS.com offers up to ~30% less than hyperscaler reserved rates, with short-term and long-term contracts and no multi-year lock-in
Most GPU cost conversations start and end at the hourly rate. That's the wrong place to look. The rate matters, but it's rarely the main driver of the spike. This post breaks down the four real causes of GPU bill increases at cluster scale, shows you what each one actually costs in dollar terms, and explains how to address them. For the full picture on GPU pricing structures, see the GPU pricing guide.
The biggest GPU cost problem in 2026 isn't the rate. It's that most clusters spend most of their time doing nothing. Cast AI's 2026 State of Kubernetes Optimisation Report measured GPU utilisation across 23,000 production clusters on AWS, GCP, and Azure. The average: 5%. That means 95% of provisioned GPU capacity is idle at any given moment. Teams are paying for 20x more compute than their workloads actually use.
The causes are predictable. Engineers overprovision to avoid OOM errors. Clusters get stood up for a training run and left running over the weekend because reprovisioning is painful. Batch jobs finish and GPUs sit idle waiting for the next one. None of this is careless, it's rational behaviour under a scarcity mindset that made sense in 2023 and is costing serious money in 2026.
According to Cast AI's 2026 State of Kubernetes Optimisation Report, average GPU utilisation across 23,000 measured production clusters sits at 5%, meaning teams pay for 20x more GPU capacity than their workloads actually consume at any given moment.
The fix isn't more GPUs. It's using the ones you have. Continuous batching on inference workloads, proper vLLM configuration, and turning off clusters when jobs complete can take real-world utilisation from 5% to 70%+ without touching your contract or your rate. For the full inference optimisation playbook, see the KV cache and inference cost guide.
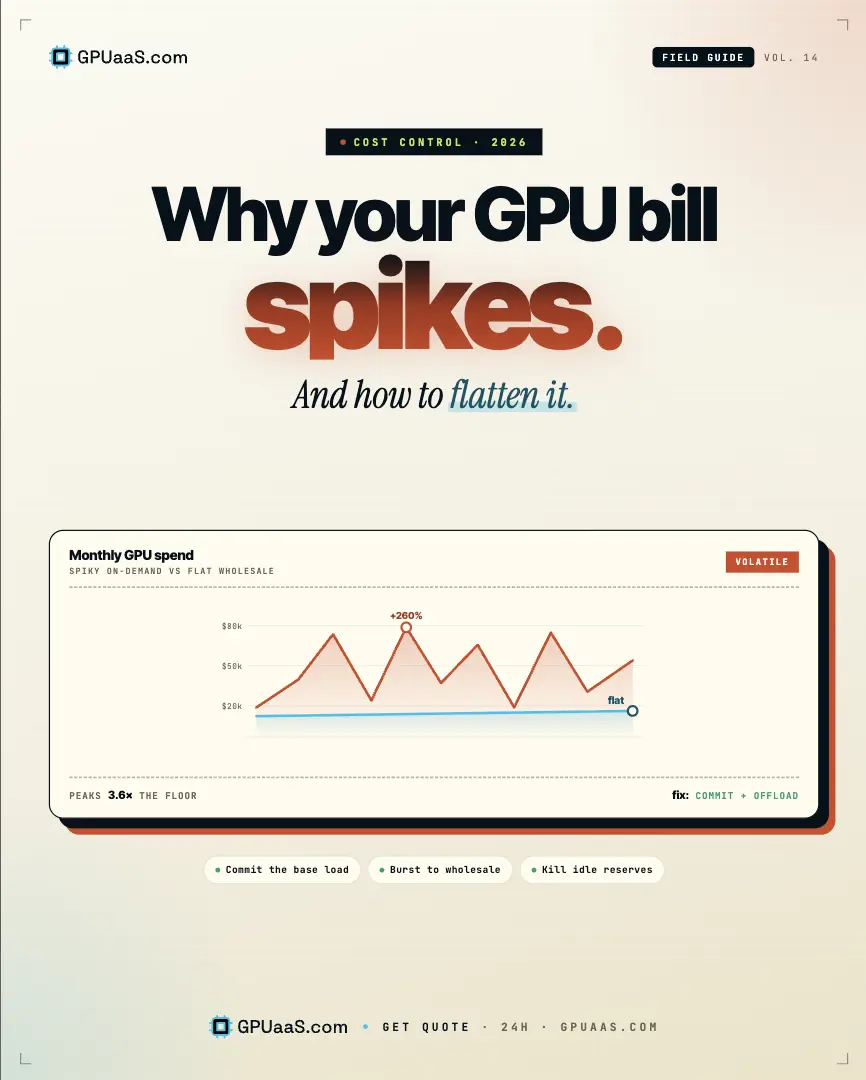
Most teams negotiate SaaS contracts hard. Almost none negotiate their GPU rate. That's where the money is. A difference of 50 cents per GPU per hour sounds small. At cluster scale over a realistic deployment period, it's a hiring decision.
$173,000
saved on an 80-GPU H100 cluster over 6 months at a $0.50/GPU/hr rate difference
80 GPUs x $0.50 x 24hrs x 180 days. GPUaaS.com offers up to ~30% less than hyperscaler reserved rates.
The compounding is what gets people. Here's what a rate difference of $0.50/GPU/hr actually means across different cluster sizes over 6 months:
| Cluster size | Rate gap | 6-month saving | What that buys |
|---|---|---|---|
| 8-GPU H100 cluster | $0.50/GPU/hr | ~$17,000 | A month of eng time |
| 32-GPU H100 cluster | $0.50/GPU/hr | ~$69,000 | A senior ML hire |
| 80-GPU H100 cluster | $0.50/GPU/hr | ~$173,000 | Two senior engineers |
| 256-GPU H100 cluster | $0.50/GPU/hr | ~$553,000 | Your next model training run |
Based on 24/7 operation over 180 days. GPUaaS.com offers up to ~30% less than hyperscaler reserved rates.
GPUaaS.com offers up to ~30% less than hyperscaler reserved rates, with both short-term and long-term contracts, without the 1 to 3-year lock-in hyperscaler Savings Plans typically require. Get a quote and see what the gap looks like for your workload.
A $0.50/GPU/hr rate difference on an 80-GPU H100 SXM5 cluster running continuously over 6 months compounds to $172,800 in savings or overspend. GPUaaS.com offers up to ~30% less than hyperscaler reserved rates, with no multi-year commitment required.
On hyperscalers, accessing a meaningful GPU rate discount requires committing to a 1-year Savings Plan at minimum. 3-year Reserved Instances unlock better rates but tie up capital for longer than most AI workloads can predict with confidence. Teams that guess wrong pay for it twice: once in the overpay on rate, and again if the workload evolves faster than the contract allows.
The right contract length depends on your utilisation confidence. If you're running production inference at 75%+ utilisation with stable demand, a longer commit makes economic sense. If you're in pre-production, experimenting with model architectures, or scaling up toward a target that isn't certain yet, locking into a 1 to 3-year hyperscaler commit is the wrong call.
⚠ Watch out
Hyperscaler reserved GPU contracts are typically non-cancellable. If your workload changes, your architecture shifts, or you find a better rate mid-term, you continue paying for the full commit. Build that risk into your total cost model before signing.
GPUaaS.com offers both short-term and long-term contracts, without the multi-year lock-in that hyperscaler reserved pricing typically requires. You can start shorter as your workload matures and extend as your confidence grows. For a full framework on when each contract type makes sense, see the reserved vs on-demand GPU guide.
Flattening a GPU bill isn't one change. It's four levers, and each one compounds on the others. Fix utilisation first because it has the biggest immediate impact. Then address rate, hidden costs, and contract structure in order.
Your search for enterprise GPU compute ends here.
NVIDIA infrastructure at rates hyperscalers won't offer you. H100, H200, B200, B300 clusters. Short-term and long-term contracts. Competing quotes within 24 hours.
Get a quote and see what you'd saveLast reviewed: June 3, 2026. GPU utilisation data from Cast AI 2026 State of Kubernetes Optimisation Report (April 2026, 23,000 clusters). AWS H200 price increase from Amplix/SDxCentral reporting (January 2026). Egress rates from AWS and Azure published pricing pages (June 2026). GPUaaS.com rates are indicative, contract-based, and quote-dependent on cluster size and contract length.







