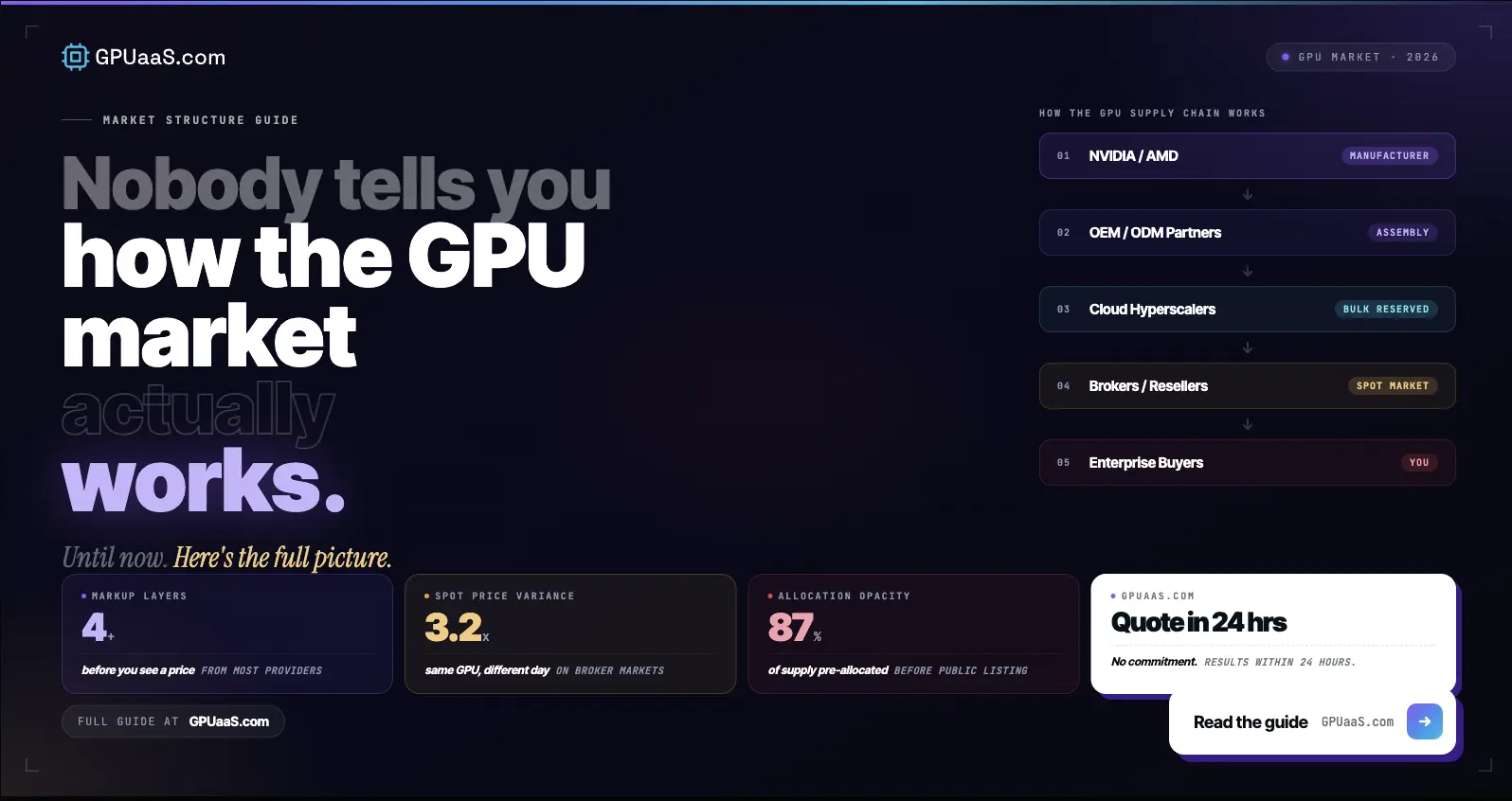
SemiAnalysis described finding GPU compute in early 2026 as "like trying to book airplane tickets on the last flight out: high prices and almost no availability." By March 2026, it had become nearly impossible to find H100, H200, or B200 rental capacity for any term. Half the providers they contacted were completely sold out. Most of the rest had no Hopper capacity coming off contract at all.
- H200 and B200 lead times are running 36 to 52 weeks due to HBM3e memory constraints and TSMC CoWoS packaging capacity fully allocated through at least mid-2027
- Microsoft, Google, Meta, and Amazon placed multi-billion-dollar Blackwell forward orders in 2025, consuming most of NVIDIA's allocation capacity through end of 2026 and into 2027
- H100 1-year contract prices rose 15 to 20% month-on-month in February and March 2026 (SemiAnalysis). Some H100 contracts are being renewed at the same rate through 2028
- The capacity that exists right now is moving fast. GPUaaS.com gives buyers early visibility into available clusters before they are committed elsewhere
- Teams that secure GPU capacity in the next 90 days will have a 12 to 18 month structural advantage over those who wait for the market to ease
The GPU market in 2026 does not behave like any other infrastructure procurement category. You cannot put in a ticket and wait. You cannot rely on annual planning cycles. The capacity that is available today will not be available next month, and the capacity that is not available today may not appear for 12 months or more.
Most enterprise procurement teams are running six to twelve month planning cycles for a market that moves in weeks. That mismatch is costing teams their AI roadmaps.
◆ WHY CAPACITY DISAPPEARS
The structural reasons GPU capacity windows close so fast
Three forces drive the speed at which GPU capacity moves off the market.
Hyperscalers reserved the supply chain first. Microsoft, Google, Meta, and Amazon placed multi-billion-dollar forward orders for Blackwell GPUs in 2025. Those orders consumed most of NVIDIA's available allocation capacity through the end of 2026 and into 2027, according to Spheron's April 2026 GPU shortage analysis. Mid-market and enterprise customers who previously purchased through standard channels or direct resellers were effectively crowded out. What remains available in the market is the residual allocation after hyperscalers have taken their share.
The memory bottleneck has no near-term fix. H200 and the Blackwell lineup all require HBM3e. SK Hynix supplies the majority of HBM stacked memory for NVIDIA's data center products. TSMC's CoWoS packaging process, required to bond HBM dies onto the GPU substrate, is fully allocated through at least mid-2027. Samsung and Micron are ramping HBM capacity but neither will meaningfully ease the shortage before late 2026 at the earliest. This is not a production ramp problem that resolves in a quarter.
Demand is accelerating faster than supply. Multi-agent workloads executing multi-step workflows at high concurrency, native media generation, and parabolic growth in inference demand are all driving GPU consumption beyond prior forecasts. SemiAnalysis tracks the contract market across every major GPU type and term length. Their March 2026 data showed lead times for new Blackwell deployments extending into June and July, with most clusters being absorbed immediately upon becoming available.
SemiAnalysis reported in April 2026: "Hunting for even 8 nodes (64 GPUs) of H100s or H200s is not easy. Half the providers we asked were completely sold out, and most providers will simply respond they have no capacity of Hopper GPUs coming off contract at all."
For a full breakdown of H100 vs H200 vs B200 availability and which workloads each serves in 2026, the GPU rental decision guide covers the comparison in detail.
◆ THE PRICING SIGNAL
What GPU contract pricing is telling you about scarcity right now
H100 1-year contract prices broke above $2 per GPU-hour in late January 2026 and then rose 15 to 20% month-on-month by mid to late February. SemiAnalysis projects a further 15 to 20% increase by the end of March. This is not a spot price spike. These are committed contract rates moving at a pace that has no precedent in enterprise infrastructure pricing.
Some H100 contracts are being renewed at the exact same rate they were signed at two to three years ago. Some are being renewed on four-year terms through 2028. The holders of those contracts know something buyers waiting for the market to normalize do not: normalized supply for Hopper-class GPUs is not coming.
H200 lead times are running 50 to 65 days for Q2 2026 needs under the most optimistic sourcing scenarios, and 36 to 52 weeks through standard hyperscaler channels. B200 availability through AWS p6 spot instances is seeing customers competing to pay $14 per GPU-hour, with some major neoclouds no longer selling single nodes at all.
36-52wks
standard lead time for H200 and B200 GPUs through hyperscaler channels in 2026, driven by HBM3e constraints and TSMC CoWoS packaging capacity allocated through mid-2027
Lyceum Technology / Spheron GPU Shortage Analysis, April 2026
For a detailed look at how H100 pricing compares to hyperscaler rates and what the gap actually represents, the H100 cost per hour breakdown has the numbers. And for the billing model implications of committing now versus waiting, the reserved vs on-demand GPU guide covers the decision framework.
◆ THE PROCUREMENT MISMATCH
Why enterprise procurement cycles are the wrong tool for this market
Traditional enterprise procurement works on annual budget cycles. A business unit identifies a need in Q3, it enters the budget process for the following year, approval comes in Q1, procurement goes to market in Q2. For servers, storage, and networking, this timeline works because those markets have predictable supply and pricing.
The GPU market in 2026 moves on a different clock entirely. Capacity windows open and close in days, not quarters. A cluster that is available on Monday may be committed to another buyer by Wednesday. Pricing that looks manageable in January can be 30 to 40% higher by March. An RFQ that takes three weeks to go through internal approval arrives at a market where the capacity in the original quote no longer exists.
The enterprises winning on GPU access in 2026 are not the ones with the largest budgets. They are the ones with the shortest decision cycles. They have pre-approved frameworks for GPU procurement that allow them to move within 24 to 48 hours of capacity becoming available. They have provider relationships that surface availability before it is publicly listed. And they have already done the workload qualification work so that when a cluster appears, they know immediately whether it fits.
The uvation.com H100 availability analysis described the shift precisely: "Position in the queue is now a critical asset." The same statement applies even more forcefully in 2026, when the queue itself is harder to join.
For context on how this interacts with cost, the GPU quote hidden costs breakdown covers why the price you are quoted and the price you end up paying are often different things.
◆ WHAT IS ACTUALLY AVAILABLE
Where GPU capacity actually exists in the market right now
Hyperscaler on-demand inventory for H100, H200, and B200 is constrained but not zero. AWS, Azure, and GCP maintain availability for on-demand instances, but that availability is intermittent and pricing reflects scarcity. Reserved and committed capacity through hyperscaler channels carries the 36 to 52 week lead times described above.
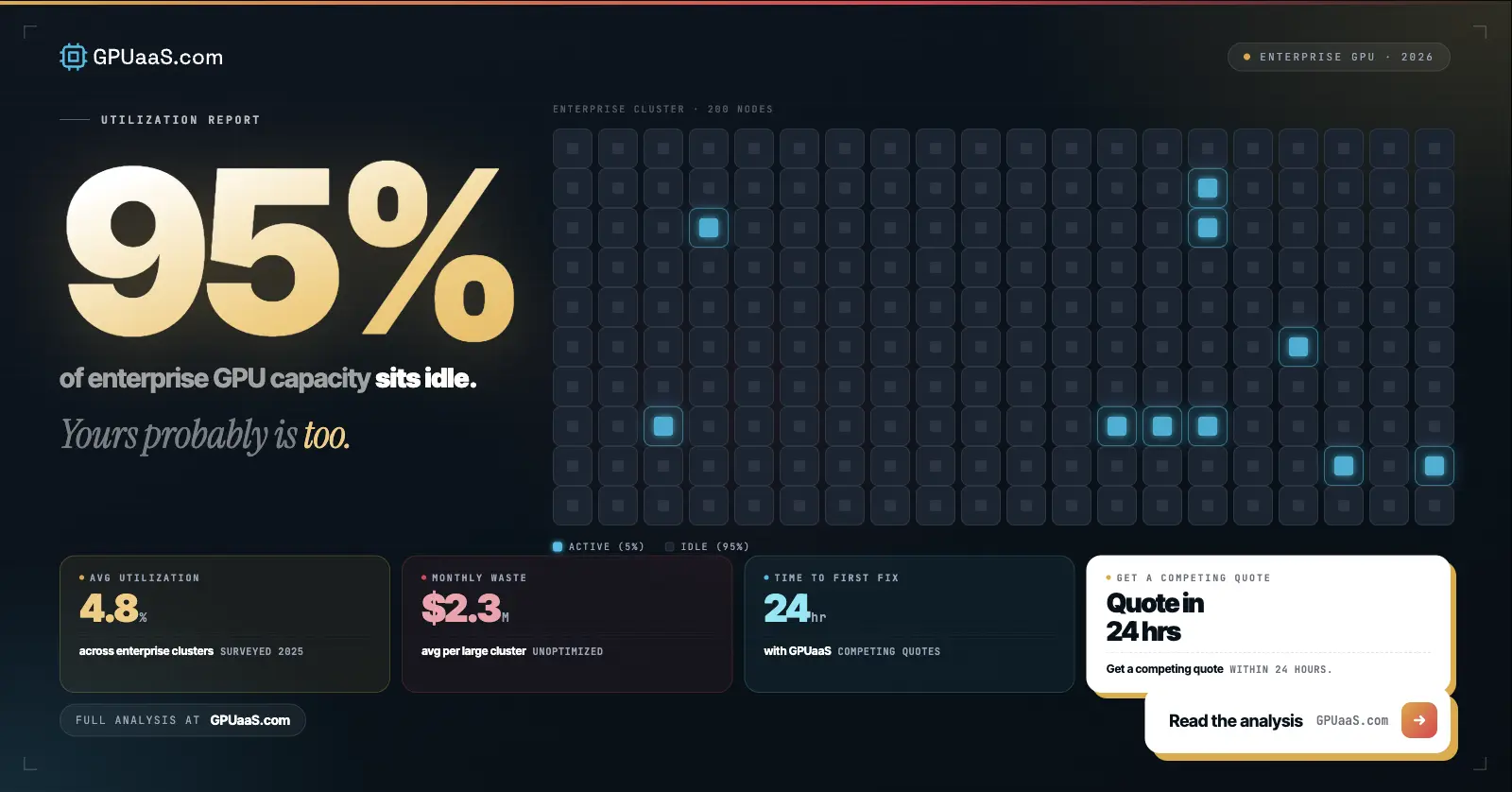
The more accessible supply exists in two places that most enterprise buyers are not looking. First, purpose-built GPU infrastructure providers and neoclouds that source hardware independently of hyperscaler channels. These providers have maintained meaningful H100 and H200 inventory through direct relationships with hardware vendors and earlier procurement cycles. Second, enterprises with idle GPU capacity that are open to external monetization of clusters they are not currently using. This supply is not listed on any public marketplace and is not visible to buyers running standard RFQ processes.
GPUaaS.com operates at the intersection of both supply pools. Buyers submit requirements and receive quotes from vetted providers within 24 hours. The inventory includes clusters that are not publicly listed, sourced through provider relationships built over time. That early visibility into available capacity is the practical difference between securing a cluster this month and joining a waitlist that resolves in six months.
The B200 GPU availability report for Q2 2026 covers where Blackwell capacity actually exists right now. And for buyers trying to decide whether H100, H200, or B200 is the right tier for their workload given current availability and pricing, the H200 vs H100 rental decision guide and the H200 vs B200 comparison both cover the tradeoffs.
◆ WHAT TO DO NOW
How to position your organization to move when capacity appears
The difference between teams that secure GPU capacity in 2026 and teams that wait 36 to 52 weeks is not budget. It is preparation. Three things separate the organizations that move fast from those that do not.
Pre-approved procurement frameworks. Getting internal approvals after capacity appears is too slow. The teams winning on GPU access have standing approval to act within a defined budget envelope when qualifying capacity surfaces. The procurement work happens before the opportunity, not in response to it.
Completed workload qualification. Knowing in advance which GPU tier your workload requires, what minimum cluster size you need, and what interconnect specifications matter means you can evaluate a cluster in minutes rather than weeks. Doing that qualification now against available options costs nothing. Doing it in response to a live availability window costs you the window.
Multi-provider visibility. Relying on a single hyperscaler channel means you see only a fraction of available capacity. Building relationships with purpose-built providers and marketplace intermediaries before you have an urgent need means you have supply options when the window opens. The enterprises with the best GPU access in 2026 are not the ones with the deepest hyperscaler relationships. They are the ones with the broadest provider network.
See what GPU capacity is available right now.
H100, H200, B200, B300 clusters. Vetted providers. Quotes within 24 hours. No buyer fees.
View available GPU clusters◆ FAQ
Frequently asked questions
H200 and B200 lead times through standard hyperscaler channels are running 36 to 52 weeks in 2026, driven by HBM3e memory supply constraints and TSMC CoWoS packaging capacity fully allocated through at least mid-2027. Through purpose-built providers and marketplace intermediaries like GPUaaS.com, lead times can be materially shorter for clusters already in inventory, with quotes available within 24 hours.
Microsoft, Google, Meta, and Amazon placed multi-billion-dollar forward orders for Blackwell GPUs in 2025, consuming most of NVIDIA's available allocation capacity through end of 2026 and into 2027. These orders were driven by accelerating inference demand, competitive pressure to maintain AI service capacity, and a structural shift toward multi-agent workloads that consume significantly more compute than single-turn inference. The effect on mid-market and enterprise buyers was direct: less allocation available through standard channels, longer lead times, and higher pricing for remaining inventory.
Samsung and Micron are ramping HBM production but neither will meaningfully ease the shortage before late 2026 at the earliest. TSMC CoWoS packaging capacity is fully allocated through at least mid-2027. NVIDIA's Rubin architecture is expected in late 2026, which will introduce another demand wave for next-generation supply. The structural case for a supply normalization that brings lead times below 12 weeks is not strong before mid-2027, and even that assumes demand growth does not continue to outpace production gains.
The fastest path to GPU capacity in 2026 is through providers with existing inventory rather than new procurement channels. Purpose-built GPU infrastructure providers and marketplace intermediaries like GPUaaS.com have clusters available that are not visible through hyperscaler portals. Buyers who submit requirements through GPUaaS.com receive quotes within 24 hours from vetted providers with available inventory. The parallel strategy is completing workload qualification and internal approval frameworks in advance, so that when capacity is identified, you can commit in hours rather than weeks.
Given current pricing trends, longer commitment terms offer meaningful protection against further rate increases. SemiAnalysis data shows H100 1-year contract prices rising 15 to 20% month-on-month in early 2026, with some contracts being renewed at the same rate through 2028. For teams with confirmed workload demand and stable utilization patterns, committing to a 12 to 24 month term locks in current pricing before the next upward move. The risk of over-committing to underutilized capacity must be weighed against the cost of waiting in a market where prices are rising month-on-month. The reserved vs on-demand GPU guide covers the decision framework in full.
Relatively, yes. H100 SXM5 inventory is tighter than it was in mid-2025 but more accessible than H200 or B200 through non-hyperscaler channels. NVIDIA has shifted production focus to Blackwell, which means fewer new H100s are entering the market, but existing H100 inventory is available through purpose-built providers and the secondary market. H200 and B200 face the most acute constraints due to HBM3e requirements. For buyers whose workloads run efficiently on H100 capacity, this is the most accessible tier in the current market. The H100 vs H200 vs B200 rental guide covers the workload matching question in detail.
Last reviewed: 26 June 2026. GPU availability and lead time data from SemiAnalysis GPU Rental Price Index (April 2026), Spheron GPU Shortage Analysis (April 2026), and Lyceum Technology EU GPU Availability Guide (April 2026). Browse current GPU cluster availability on GPUaaS.com.