++ NEW ++ NVIDIA B200 (EU) · H200 (US) · RTX 6000 Pro (US) · Get a quote →
Blog ▸ 95% of Enterprise GPU Capacity Is Sitting Idle. Yours Probably Is Too.
GPU Infrastructure
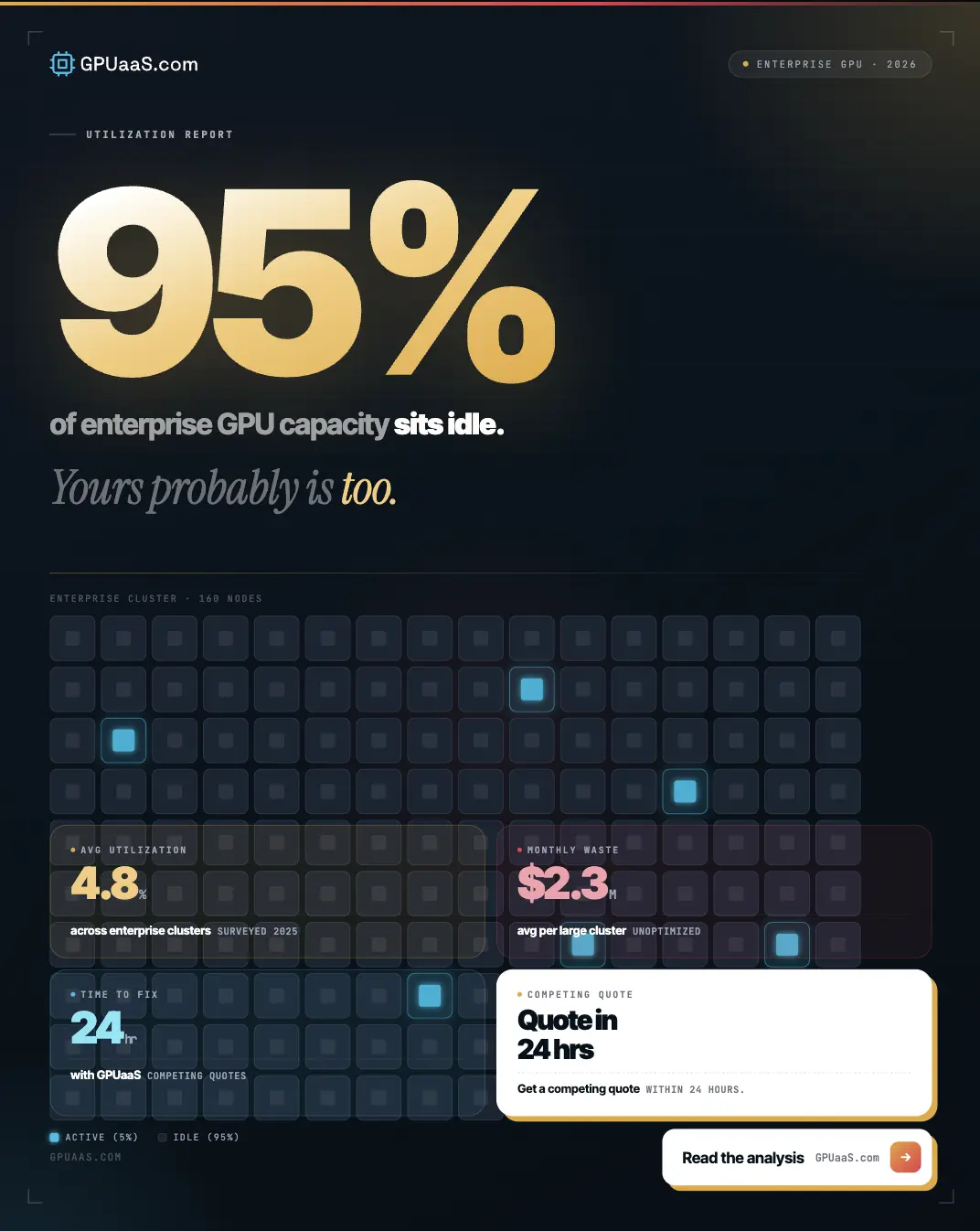
Enterprise GPU utilization averages 5% across 23,000 production clusters. 95% of provisioned capacity is idle right now, paid for, depreciating, and doing nothing. Here is why that happens and what to do about it.
95% of Enterprise GPU Capacity Is Sitting Idle. Yours Probably Is Too.
GPUaaS.com Team
GPU Infrastructure
June 24, 2026
Enterprise GPU utilization averages 5% across production Kubernetes clusters, according to Cast AI's 2026 State of Kubernetes Optimization Report, drawn from telemetry across 23,000 real clusters. That means 95% of provisioned GPU capacity is sitting idle right now. Paid for. Running up power and cooling bills. Doing nothing.
Key takeaways
Enterprise GPU utilization averages 5% across 23,000 production clusters (Cast AI, 2026). 95% of capacity is idle at any given moment
An idle GPU costs dollars per hour. An idle CPU costs cents. The cost asymmetry is why this matters more than any other infrastructure efficiency problem in 2026
H100 SXM5 cards that sold for $40,000 in 2023 now move for $6,000 to $15,000 on secondary markets. The depreciation clock does not stop while the GPU sits idle
84.7% of organizations report AI project delays due to GPU availability (Civo, 2025) while simultaneously carrying significant idle GPU capacity they cannot access internally
Enterprises with idle GPU clusters can monetize that capacity through GPUaaS.com, connecting to vetted buyers without releasing ownership of the hardware
If your organization bought GPU capacity in the past two years, there is a high probability that most of it is not being used right now. Not because your team is inefficient. Because this is how enterprise GPU procurement works.
Teams reserve capacity under time pressure. Projects get delayed. Workloads change. The hardware sits. And every hour it sits, it costs money twice: once in the hourly rate or amortized capex, and once in the value it loses as newer GPU generations ship.
◆ THE PROBLEM
Why enterprise GPU utilization sits at 5%
The Cast AI data covers 23,000 Kubernetes clusters across AWS, GCP, and Azure. These are production environments, not test clusters or development sandboxes. The 5% figure reflects what enterprises are actually doing with the GPU capacity they are paying for in production.
Laurent Gil, co-founder and president of Cast AI, framed it plainly: "A GPU sitting idle costs dollars per hour. A CPU sitting idle costs cents. And 95% of GPU capacity is doing nothing."
How does a fleet reach 5% utilization when GPUs cost this much? The procurement story explains it. An enterprise joins a hyperscaler waitlist. Nothing happens for weeks. Then a call arrives: there are 36 GPUs available on a one-year or three-year commitment. The three-year option is cheaper. Five other companies on the list will take them if you do not. The fear of losing allocation is acute. The commitment gets signed.
Then the project the GPUs were bought for takes longer to reach production than expected. Or the model turns out to need a different configuration. Or the team running it loses headcount. The cluster sits. The billing continues.
VentureBeat's Q1 2026 AI Infrastructure Tracker puts it more bluntly: at 5% utilization, for every dollar spent on silicon, 95 cents is essentially wasted. In any other department, a 95% waste metric would be a firing offense. In AI infrastructure, it was called "preparedness."
The same FOMO that drove overcommitment at the procurement stage now prevents releasing the idle capacity. Nobody wants to give back a GPU allocation they might need in three months. So the fleet stays at 5%, billed by the hour, and the cycle tightens.
◆ THE COST
What idle GPU capacity actually costs your organization
The hourly cost is the visible part. An H100 running at 5% utilization on a hyperscaler at $6.88 per GPU-hour has an effective cost of $137.60 per hour of actual compute work. At 8 GPUs in a cluster, that is $1,100 per hour of real work, billed as $55 per hour of theoretical capacity. Across a 720-hour month, the gap between what you pay and what you use is significant enough to appear on a P&L.
The depreciation cost is less visible but equally real. H100 SXM5 cards that sold for $40,000 in late 2023 now trade for $6,000 to $15,000 on secondary markets, according to CloudZero's May 2026 pricing analysis. That is a hardware asset losing 60 to 85% of its peak value in under three years. For owned infrastructure, every month of idle time is a month where that depreciation accrues without generating any offsetting revenue or output.
The power and cooling cost runs regardless of utilization. A data center GPU pulls 300 to 700 watts under load. It pulls a meaningful fraction of that at idle. At $0.12 per kWh, a single idle H100 in a server running 24/7 costs $250 to $600 per year in power alone, before cooling overhead is applied.
$401B
the estimated annual cost of the 5% GPU utilization problem across enterprise AI infrastructure globally (VentureBeat, 2026)
VentureBeat Q1 2026 AI Infrastructure Tracker
For context on how these costs compound across a full cluster lifecycle, the real TCO of a GPU cluster in 2026 covers every cost category with worked examples. And for the specific economics of idle cost versus compute cost, the GPU billing models guide covers how commitment structures interact with utilization.
◆ THE PARADOX
Idle GPU capacity and GPU scarcity are the same problem
Here is the structural contradiction at the center of the 2026 GPU market. 84.7% of organizations report AI project delays due to GPU availability (Civo, 2025). Those same organizations are collectively running their GPU fleets at 5% utilization.
The teams that cannot get GPU capacity and the teams sitting on idle GPU capacity are often in the same building. Sometimes in the same company. The capacity exists. It is just allocated to a team or project that is not using it, with no mechanism for other teams to access it.
Speediyo's Stranded Compute research describes this as "stranded compute": capacity that exists inside an enterprise but cannot be accessed by the teams that need it, because allocation structures have no mechanism for cross-team sharing. The technical tools for GPU orchestration and utilization monitoring exist. They do not fix this problem because the fix requires an organizational intervention, not a software one.
For enterprises with owned GPU infrastructure, there is a third option beyond internal reallocation or leaving hardware idle: monetizing the capacity externally. Connecting idle clusters to vetted external buyers generates revenue from hardware that would otherwise depreciate unused. The GPU procurement cost breakdown and the GPU bill optimization guide both cover the cost side of this equation in detail.
◆ THE DEPRECIATION CLOCK
Why every month of idle time costs more than the last
GPU depreciation in 2026 does not follow historical hardware patterns. H100 cards held 75 to 85% of acquisition value through the first 24 months. After that, the drop accelerated sharply as Blackwell supply ramped. H100 SXM5 cards that peaked at $50,000 in mid-2024 secondary markets now trade at $6,000 to $15,000.
The driver is not obsolescence in the traditional sense. H100s remain capable hardware for inference workloads. The driver is the performance delta of Blackwell. B200 and B300 GPUs are materially faster for certain workloads, which means providers running H100s for inference need to charge less to remain competitive. Lower cloud rates for H100 translate directly to lower secondary market values for owned H100 hardware.
Silicon Data's H100 market value analysis puts it clearly: for the H100, the risk is not slow drift. It is sudden resets. The asset can reprice quickly when supply conditions or buyer sentiment shifts. For finance teams carrying H100 clusters on a standard five-year depreciation schedule, that represents a significant gap between book value and market value.
For enterprises with owned H100 or H200 clusters sitting underutilized, the window to capture meaningful market value from that capacity is narrowing. The H200 vs H100 rental decision guide covers the utilization economics in detail, and the H100 vs H200 vs B200 comparison covers where each generation sits in 2026.
◆ THE OPPORTUNITY
What enterprises with idle GPU capacity can do about it
For enterprises running owned GPU infrastructure at low utilization, three options exist. None of them require giving up the hardware or the ability to reclaim it when internal demand returns.
Internal reallocation. Making idle capacity visible and accessible to other teams within the organization. This requires the organizational infrastructure: a shared scheduling layer, a cost allocation model, and executive mandate that GPU capacity is a corporate resource rather than a team asset. Most enterprises have the technical tools. Few have done the organizational work.
External monetization. Listing idle capacity with a GPU matchmaking service that connects enterprise providers to vetted buyers. GPUaaS.com operates as the matchmaking layer between enterprises with idle GPU clusters and buyers who need capacity. The process involves specifying the cluster, the availability window, and the rate. GPUaaS handles the buyer qualification and the match. The enterprise provider retains ownership and the ability to reclaim capacity when internal projects need it.
Strategic disposition. For hardware that has passed its useful life for internal workloads, selling into the secondary market while resale values remain meaningful. As the Silicon Data analysis notes, the risk for H100 holders is sudden resets rather than slow drift. Enterprises that plan disposition proactively recover materially more than those who wait.
Turn idle GPU capacity into revenue.
GPUaaS.com connects enterprises with idle GPU clusters to vetted buyers. Any model, any region. Flexible terms.
Average GPU utilization across enterprise Kubernetes clusters is 5%, according to Cast AI's 2026 State of Kubernetes Optimization Report, drawn from production telemetry across 23,000 clusters on AWS, GCP, and Azure. That means 95% of provisioned GPU capacity is idle at any given moment. CPU utilization averages 8% and memory 20% across the same clusters, but the cost asymmetry makes GPU idle time the most expensive of the three.
The procurement dynamic is the primary driver. Hyperscaler allocation calls arrive with short decision windows and multi-year commitment requirements. Enterprises commit under FOMO conditions rather than against confirmed workload demand. Projects then take longer to reach production than expected, configurations change, or teams lose capacity. The FOMO that drove the initial commitment also prevents releasing the idle capacity, because teams do not want to lose an allocation they might need later.
H100 SXM5 cards held 75 to 85% of acquisition value through the first 24 months. Cards that sold for $40,000 in late 2023 now trade for $6,000 to $15,000 on secondary markets as of mid-2026, according to CloudZero's pricing analysis. The driver is Blackwell supply ramping, which makes H100 providers less competitive for inference workloads and compresses secondary market pricing. Silicon Data's analysis describes the risk as sudden resets rather than gradual decline.
Yes. GPU matchmaking platforms like GPUaaS.com connect enterprises with idle clusters to vetted buyers without requiring a long-term transfer of ownership. The enterprise lists their available capacity, availability window, and required rate. GPUaaS handles buyer qualification and matching. The enterprise retains ownership and can reclaim the hardware when internal demand returns. The model is closer to commercial real estate subletting than to hardware disposal.
Stranded compute describes GPU capacity that exists inside an enterprise but cannot be accessed by the teams that need it, because siloed allocation structures have no mechanism for cross-team sharing. An AI team in one division may have idle H100 capacity while another division waits months for GPU availability. The technical tools for orchestration and utilization monitoring exist. They do not fix stranded compute because the underlying problem is organizational: no shared scheduling layer, no cross-team cost visibility, and no executive mandate treating GPU capacity as a corporate resource rather than a team asset.
Significantly and in multiple directions simultaneously. First, the per-useful-compute cost inflates in direct proportion to idle time: at 5% utilization, effective cost per useful compute hour is 20 times the headline rate. Second, owned hardware depreciates whether it runs or not, so idle time converts depreciation into pure cost with no offsetting output. Third, power and cooling costs continue at idle. At $0.12 per kWh, a single idle H100 server running 24/7 costs several hundred dollars per year in power alone before cooling is applied. The real TCO of a GPU cluster in 2026 covers all of these cost categories in detail.
Last reviewed: 25 June 2026. Utilization data from Cast AI 2026 State of Kubernetes Optimization Report (23,000 clusters). Depreciation data from CloudZero, Silicon Data, and Compute Exchange secondary market analysis, May-June 2026. Browse current GPU cluster availability on GPUaaS.com.