

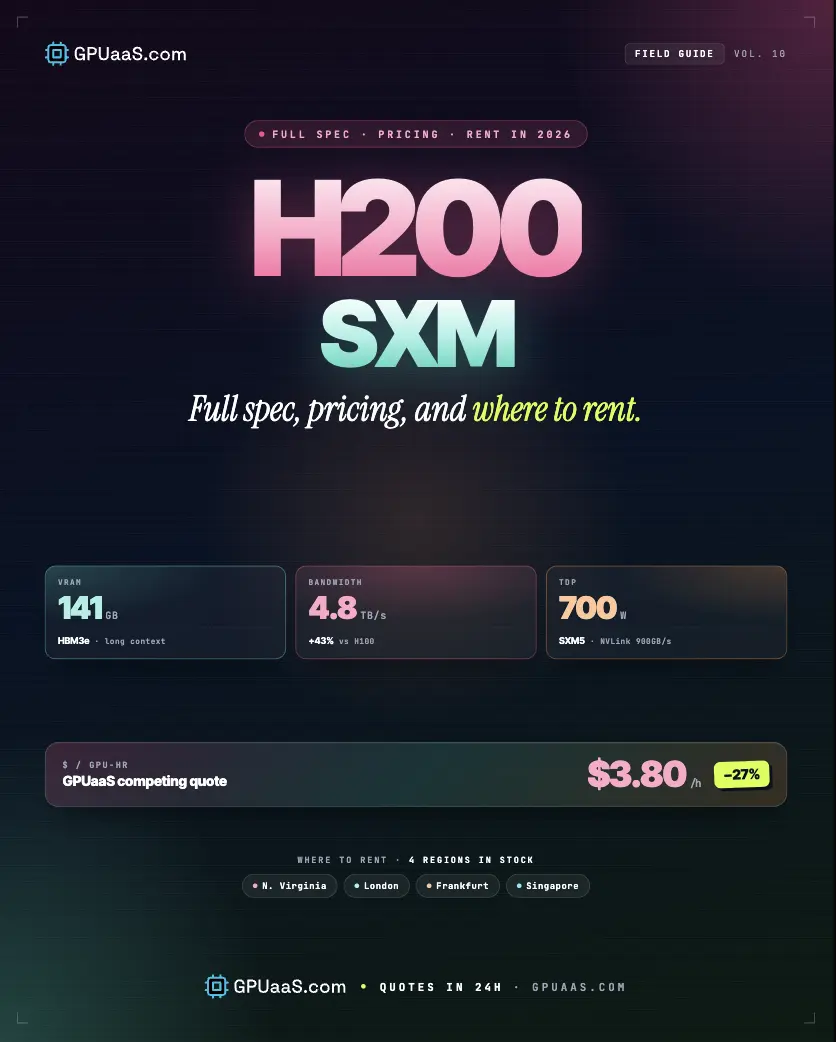
The NVIDIA H200 SXM delivers 141 GB of HBM3e memory at 4.8 TB/s bandwidth, 76% more VRAM and 43% more bandwidth than the H100 SXM5. On memory-bound inference workloads like Llama 3 70B, that single hardware difference translates to a 45% throughput gain. Rental pricing starts at $3.50/GPU/hr on wholesale providers like GPUaaS.com in 2026.
- H200 SXM carries 141 GB HBM3e at 4.8 TB/s, compared to H100 SXM5's 80 GB HBM3 at 3.35 TB/s. Identical Hopper compute engine, FP8 Transformer Engine, and NVLink 4.0 interconnect
- MLPerf Inference v4.1: H200 SXM achieves 31,712 tokens/sec on Llama 2 70B vs 21,806 for H100 SXM, a 45% throughput gain driven entirely by memory bandwidth
- H200 SXM rental starts at $3.50/GPU/hr on-demand at GPUaaS.com, roughly 2.3x the cost of H100 SXM5 at $1.49/GPU/hr
- The H200 SXM is the right GPU for 70B+ parameter inference, 32K+ context windows, multi-modal workloads exceeding 80 GB VRAM, and production serving of quantised 405B models
- For sub-70B models at standard context lengths, H100 SXM5 at $1.49/hr delivers near-identical throughput at less than half the cost. The H200 premium isn't justified there
| Spec | H200 SXM | H100 SXM5 |
|---|---|---|
| Architecture | Hopper (GH100) | Hopper (GH100) |
| GPU Memory | 141 GB HBM3e | 80 GB HBM3 |
| Memory Bandwidth | 4.8 TB/s | 3.35 TB/s |
| FP8 Tensor Core TFLOPS | 3,958 TFLOPS | 3,958 TFLOPS |
| BF16 Tensor Core TFLOPS | 1,979 TFLOPS | 1,979 TFLOPS |
| FP32 (non-Tensor) | 67 TFLOPS | 67 TFLOPS |
| Interconnect | NVLink 4.0 (900 GB/s) | NVLink 4.0 (900 GB/s) |
| Form Factor | SXM5 | SXM5 |
| TDP | 700W | 700W |
| NVLink Bandwidth (8-GPU) | 7.2 TB/s | 7.2 TB/s |
| PCIe Generation | PCIe 5.0 | PCIe 5.0 |
| Launch | Q4 2023 (GA 2024) | Q2 2022 (GA 2023) |
Source: NVIDIA H200 datasheet. FP8 TFLOPS figures with sparsity.
NVIDIA didn't redesign the GPU. They upgraded the memory. The H200 uses the same GH100 die as the H100 SXM5, with identical Tensor Core counts, the same FP8 Transformer Engine, and the same NVLink 4.0 interconnect at 900 GB/s. The only hardware change is swapping HBM3 for HBM3e, which adds 61 GB of capacity and 1.45 TB/s of bandwidth.
That sounds incremental, and for compute-bound workloads it is. Dense matrix multiplications in training are bottlenecked by FLOPS, not memory. But for inference, the GPU spends most of its time loading model weights from HBM into compute units. A 43% bandwidth increase translates almost linearly to throughput, which is why the H200 delivers a 45% tokens-per-second improvement on Llama 2 70B without touching a single compute spec.
⚡ The infrastructure advantage
Because H200 uses the same SXM5 form factor and NVLink topology as H100, data centres running H100 SXM5 systems can upgrade to H200 with minimal infrastructure change. Same HGX baseboard, same power delivery, same cooling. That's why H200 SXM clusters came online quickly after NVIDIA's GA announcement. It wasn't a ground-up redesign.
According to MLPerf Inference v4.1 results, the H200 SXM achieves 31,712 tokens per second on Llama 2 70B, a 45% improvement over the H100 SXM's 21,806 tokens per second on the same benchmark.
MLPerf Inference v4.1 is the most directly comparable public benchmark for H200 vs H100 on LLM workloads. Both GPUs were tested on Llama 2 70B in server mode, which is the metric most relevant to production inference. The H200 SXM result came from NVIDIA's reference submission using TensorRT-LLM with FP8 quantisation.
MLPerf v4.1, Llama 2 70B inference throughput (tokens/sec, server mode)
Single GPU, server mode, FP8. Source: MLCommons MLPerf Inference v4.1.
The benchmark reflects a specific workload: long context, large model, production-style batching. For smaller models (7B to 13B), the H200's bandwidth advantage narrows because those weights fit comfortably in H100's 80 GB with room to spare for KV cache. The gap widens as model size and context length grow, both of which are trending upward in 2026 production deployments.
On FP8 fine-tuning workloads for 70B+ models, the H200 typically runs 30 to 40% faster than H100 SXM5. The bandwidth difference matters for gradient checkpointing and optimiser state management at large model scale. For training runs on models under 30B, the gap shrinks to single digits and H100 is usually the more cost-efficient choice. See the H200 vs H100 rental decision guide for the full workload framework.
According to GPUaaS.com infrastructure data, H200 SXM clusters running Llama 3 70B at FP8 with continuous batching achieve roughly 24,000 tokens/sec per GPU at 80% utilisation, about 2x the throughput of a single A100 80GB on the same workload.
H200 SXM pricing varies significantly by provider type. Hyperscalers like AWS, Azure, and GCP layer management fees and reserved capacity premiums on top of raw compute cost. Wholesale providers like GPUaaS.com connect buyers directly to data centre capacity without the broker markup, so the same silicon costs materially less.
Reserved pricing cuts the per-GPU rate significantly. A 1-year reserved H200 SXM contract at GPUaaS.com runs roughly $2.10/GPU/hr, about 40% below on-demand. For teams running persistent production inference, that discount pays back within 3 to 4 months of committed usage. See the reserved vs on-demand GPU guide for the break-even framework.
According to GPUaaS.com pricing data, an 8xH200 SXM cluster at wholesale on-demand rates costs $28/hr, compared to roughly $98/hr on AWS p5.48xlarge for equivalent H200 hardware, a 71% cost reduction for the same silicon.
The H200's value comes entirely from its memory advantage. If your workload doesn't stress memory capacity or bandwidth, you're paying a 2.3x hourly premium for headroom you won't use. Here's the framework.
✓ H200 SXM is the right call
✗ H100 SXM5 is the better value
H200 SXM availability is split between wholesale GPU providers and hyperscalers. Wholesale gives you lower cost and bare-metal access. Hyperscalers give you managed infrastructure and native cloud integrations at a 3 to 4x price premium.
Wholesale GPU marketplace, no broker markup
On-demand
$3.50/GPU/hr
Reserved (1-year)
~$2.10/GPU/hr
For a full comparison of H200 against the B200, NVIDIA's Blackwell-generation GPU, see the H200 vs B200 cluster comparison. For a breakdown of how wholesale pricing compares to hyperscaler rates across all GPU models, see the wholesale vs hyperscale GPU pricing guide.
Last reviewed: May 27, 2026. Pricing sourced from GPUaaS.com live cluster data and published hyperscaler rate cards. Benchmark data from MLCommons MLPerf Inference v4.1. NVIDIA H200 specs from official NVIDIA datasheet.







