Blog ▸ Your Idle H100s Are Losing $15,000 a Month. Here's What Enterprises Are Doing About It.
GPU Infrastructure
H100 cards that sold for $40,000 in 2023 now trade at $6,000 to $12,000. Most enterprise clusters run at 5% utilization. Here is how enterprises with idle GPU capacity are recovering operating costs.
Your Idle H100s Are Losing $15,000 a Month. Here's What Enterprises Are Doing About It.
GPUaaS.com Team
GPU Infrastructure
June 30, 2026
H100 cards that sold for $40,000 in 2023 are going for $6,000 to $12,000 now. That drop happened in under two years. Most enterprise teams that bought at peak are still carrying the hardware on a five-year depreciation schedule written before anyone knew prices would fall that fast.
The hardware is losing value whether it runs or not. That is the part procurement teams did not model.
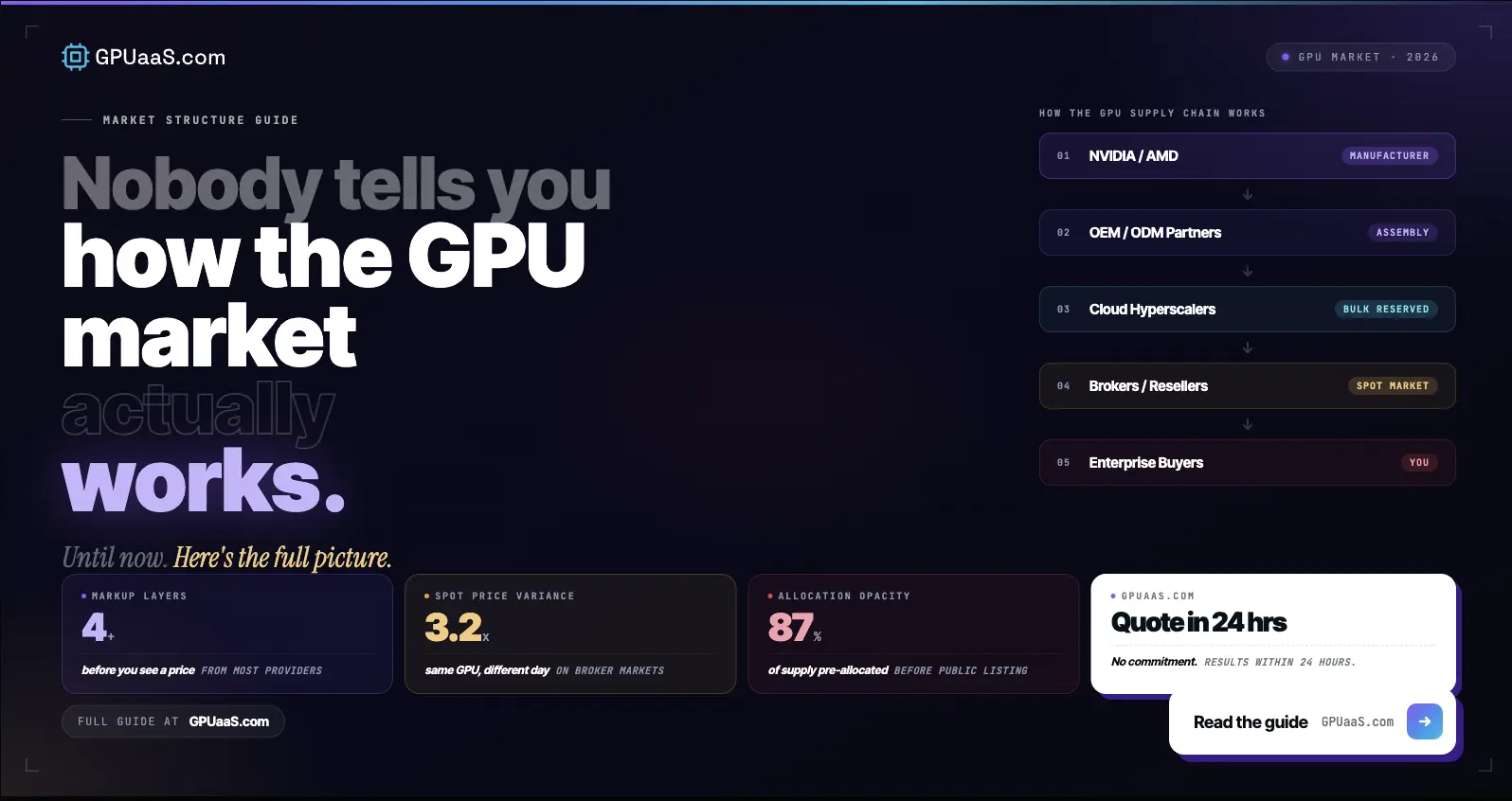
Cast AI measured GPU utilization across 23,000 production clusters last year. Average: 5%. Which means most of the teams sitting on depreciating H100 hardware are also barely using it. Power bills, cooling, amortization, all running full speed on a cluster doing almost nothing.
Some teams are starting to do something about it.
Key takeaways
H100 SXM5 cards peaked at $40,000 to $50,000 in mid-2024 and now trade at $6,000 to $15,000. The depreciation clock runs whether the GPU is doing work or not
Average GPU utilization across 23,000 enterprise production clusters sits at 5% (Cast AI, 2026). Most teams with depreciating hardware are also barely using it
Operating costs for a 16-GPU H100 cluster run $15,000 to $20,000 a month in power, cooling, and amortization. At 5% utilization the effective cost per useful compute hour exceeds $130
Enterprises with idle H100 or H200 clusters can recover 30 to 50% of monthly operating costs by listing availability windows with vetted buyers through GPUaaS.com
The window for monetizing H100 capacity is narrowing as Blackwell supply grows. Teams moving now have more buyer demand than teams moving in 12 months
◆ THE DEPRECIATION PROBLEM
Worse than it looks on the books
Standard enterprise hardware gets modeled as a three to five year capex. That math works for servers. Server hardware does not drop 70% in market value in 18 months.
H100 SXM5 cards peaked at $40,000 to $50,000 on secondary markets in mid-2024. By early 2026 they were trading at $6,000 to $15,000 according to CloudZero's May 2026 pricing analysis. The book value on a finance team's balance sheet says the hardware is worth X. The market says it is worth considerably less. That gap matters when you are trying to justify ongoing operating cost to a CFO looking at a 5% utilization number.
The operating cost itself is not trivial. Power and cooling for a 16-GPU H100 cluster runs $2,000 to $4,000 a month depending on region and energy rates. Add amortization on the original hardware purchase and you are looking at $15,000 to $20,000 a month to operate a cluster that is doing almost nothing most of the time.
At 5% utilization, the effective cost per hour of actual compute work on a $6.88/GPU/hour equivalent workload exceeds $130. The hardware is not cheap to run idle. It is just invisible because the costs hit different budget lines. For the full picture of what GPU billing actually costs at low utilization, the enterprise idle GPU problem breakdown goes deeper.
◆ WHAT ENTERPRISES ARE DOING
Three responses are emerging
VentureBeat's Q1 2026 AI Infrastructure and Compute Market Tracker described the shift from the scarcity era to the efficiency era. Teams that spent 2023 and 2024 acquiring capacity are now figuring out what to do with more of it than they can use.
Internal reallocation. Making idle capacity from one team visible to other teams in the same organization. Technically simple. Organizationally harder, because the team holding the allocation does not want to give it up even when they are not using it. Works best at organizations with centralized ML platform teams that have the authority to redistribute compute.
Secondary market disposition. Selling hardware that has genuinely passed its useful life for internal workloads. H100s are still liquid on secondary markets, though the window for good prices is narrowing as Blackwell supply grows. Teams that planned to hold hardware for five years and now want out can recover more today than they will in twelve months.
External monetization. Listing idle cluster availability windows with buyers who need short-term capacity. The hardware stays with the enterprise. The buyer gets compute time during windows when the cluster would otherwise be idle. The enterprise recovers a portion of operating costs without giving up the asset.
One team running a 16-GPU cluster at around 8% utilization recovered roughly 40% of monthly operating costs through external monetization. Their CFO stopped asking questions.
◆ THE SECURITY QUESTION
The objection that comes up every time
If an outside buyer is using your hardware, are they on your infrastructure?
No. Same principle as co-location. The buyer gets compute time during the rental window. They do not get access to your network, storage, or anything else running in your environment. The cluster is logically isolated during the rental period. Data centers have been doing multi-tenant compute isolation for decades. This is not a novel arrangement.
The practical concern is less about security and more about operational overhead. GPUaaS.com handles buyer qualification and matching on the demand side. The seller specifies the cluster, available windows, and rate. The operational footprint on the supply side is a one-time configuration, not an ongoing commitment.
◆ WHY THE TIMING MATTERS
The window is narrowing
NVIDIA shifted production focus to Blackwell. Fewer new H100s are entering the market, which keeps residual buyer demand for existing H100 inventory real. Teams whose workloads do not need Blackwell-class performance are still actively looking for H100 capacity, and they are finding it scarcer than hyperscaler channels suggest.
That demand thins as B200 supply builds and the price gap between H100 and B200 narrows. The window for recovering meaningful value from idle H100 capacity is not indefinite. The teams getting the best outcomes right now are the ones moving while buyer demand is still strong.
H200 and B200 capacity is in a different position. Lead times through hyperscaler channels are running 36 to 52 weeks. Enterprises sitting on underutilized H200 inventory have even more leverage with buyers right now because supply is tighter. The same external monetization logic applies with better economics on the supply side. The full picture of where capacity actually sits in 2026 is in the GPU capacity window breakdown.
◆ WHERE TO START
Measure first, then decide
Standard Kubernetes monitoring does not surface GPU utilization. CPU and memory show up by default. GPU usage does not. You need DCGM, Kubecost, or an equivalent layer pointed specifically at GPU metrics. Without the actual utilization number you are guessing at the size of the opportunity.
Once you have it, the math is straightforward. A cluster at 10% utilization has 90% of its capacity generating no revenue and depreciating daily. Recovering 30% of that idle time at market rates covers a real portion of operating costs. Not a rounding error on an $18,000 a month operating budget.
GPUaaS.com connects enterprise GPU supply with vetted buyers. Submit cluster details: GPU model, region, available hours, any constraints. Quotes from interested buyers come back within 24 hours. For teams on the buying side, the same platform surfaces H100 and H200 capacity from enterprise providers not listed through hyperscaler channels. Both sides of the market are active.
Turn idle GPU capacity into recovered operating costs.
H100, H200, B200 clusters. North America, EU, MEA, APAC. No buyer fees. Also on packet.ai for self-serve GPU access.
Yes. The buyer gets compute time during the rental window only. They do not get access to your network, storage, or internal systems. The cluster is logically isolated during the rental period, the same multi-tenant isolation model data centers have used for decades. GPUaaS.com also qualifies buyers before matching, so supply-side enterprises are not dealing with unknown counterparties.
It depends on utilization and availability windows. A cluster running at 8 to 10% utilization with consistent overnight and weekend availability can realistically recover 30 to 50% of monthly operating costs. Teams with larger idle windows recover more. The math: take the idle hours per month, multiply by market rate for your GPU tier, subtract any platform fees. For H100 clusters, market rates through GPUaaS.com currently run well below hyperscaler on-demand pricing, making the supply side competitive with buyers.
Standard Kubernetes monitoring does not surface GPU utilization by default. You need NVIDIA's DCGM (Data Center GPU Manager), Kubecost with GPU plugin enabled, or a similar GPU-aware observability layer. Without one of these, CPU and memory metrics will show normal-looking numbers while GPUs sit idle. Most teams are surprised by their actual GPU utilization when they first measure it properly.
Depends on whether you have internal workloads that will use the hardware within the next 6 to 12 months. If utilization is genuinely low and there is no clear internal demand roadmap, the secondary market window is better now than it will be in a year as Blackwell supply increases. If there is a real internal use case coming, external monetization of idle windows covers costs while you wait. The two options are not mutually exclusive; you can monetize idle windows while evaluating disposition on a longer timeline.
Enterprises with idle GPU clusters submit cluster details: GPU model, region, available hours, and any constraints on usage. GPUaaS.com qualifies buyers, handles matching, and manages the commercial side. The supply-side enterprise specifies availability windows and retains full control of when the hardware is available. The operational commitment on the supply side is a one-time setup, not ongoing management.
Last reviewed: 1 July 2026. H100 secondary market pricing from CloudZero GPU pricing analysis May 2026. GPU utilization data from Cast AI 2026 State of Kubernetes Optimization Report. Market shift data from VentureBeat Q1 2026 AI Infrastructure and Compute Market Tracker. Browse current GPU cluster availability on GPUaaS.com.